 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Distillation Attack and Countermeasure on Neural Network Watermarking
Jun 14, 2019
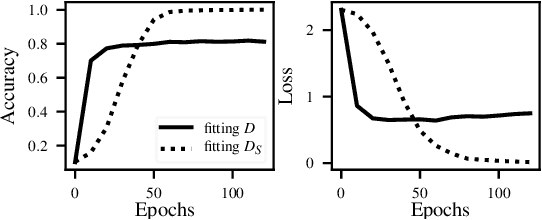
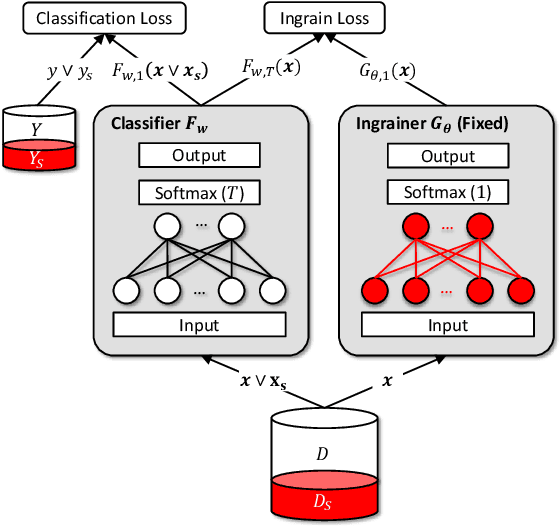

The rise of machine learning as a service and model sharing platforms has raised the need of traitor-tracing the models and proof of authorship. Watermarking technique is the main component of existing methods for protecting copyright of models. In this paper, we show that distillation, a widely used transformation technique, is a quite effective attack to remove watermark embedded by existing algorithms. The fragility is due to the fact that distillation does not retain the watermark embedded in the model that is redundant and independent to the main learning task. We design ingrain in response to the destructive distillation. It regularizes a neural network with an ingrainer model, which contains the watermark, and forces the model to also represent the knowledge of the ingrainer. Our extensive evaluations show that ingrain is more robust to distillation attack and its robustness against other widely used transformation techniques is comparable to existing methods.
Flipped-Adversarial AutoEncoders
Apr 04, 2018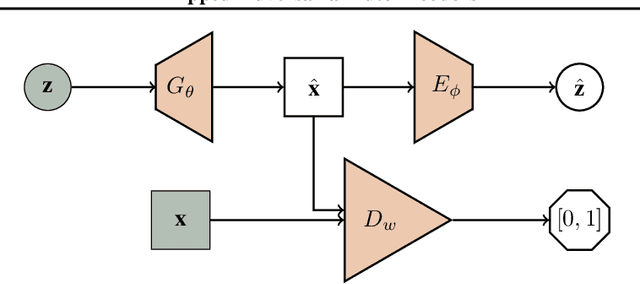
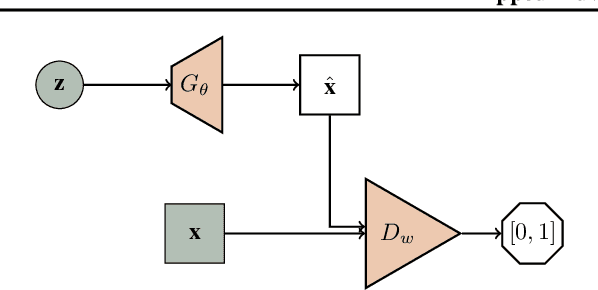
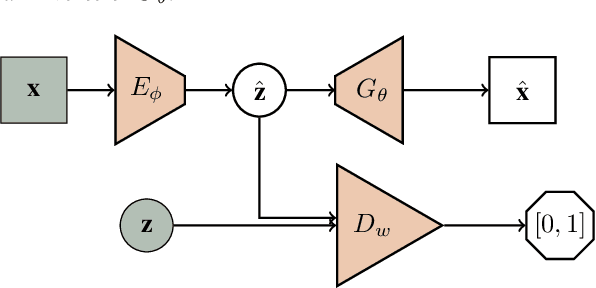
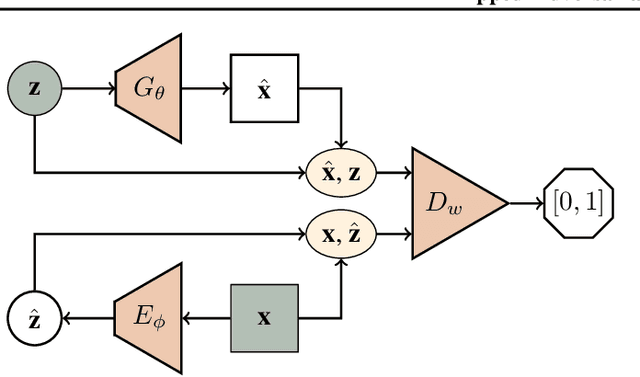
We propose a flipped-Adversarial AutoEncoder (FAAE) that simultaneously trains a generative model G that maps an arbitrary latent code distribution to a data distribution and an encoder E that embodies an "inverse mapping" that encodes a data sample into a latent code vector. Unlike previous hybrid approaches that leverage adversarial training criterion in constructing autoencoders, FAAE minimizes re-encoding errors in the latent space and exploits adversarial criterion in the data space. Experimental evaluations demonstrate that the proposed framework produces sharper reconstructed images while at the same time enabling inference that captures rich semantic representation of data.