 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Reinforcement Learning in Finance
Dec 21, 2021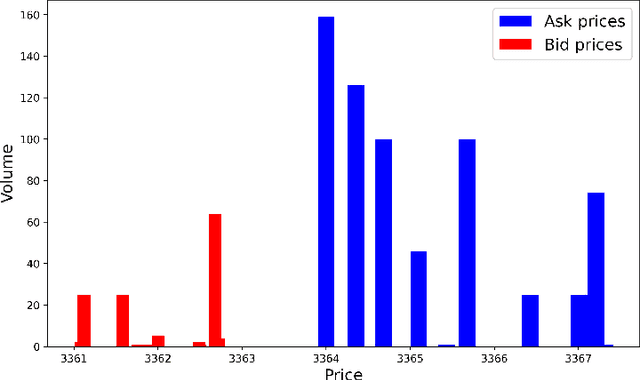
The rapid changes in the finance industry due to the increasing amount of data have revolutionized the techniques on data processing and data analysis and brought new theoretical and computational challenges. In contrast to classical stochastic control theory and other analytical approaches for solving financial decision-making problems that heavily reply on model assumptions, new developments from reinforcement learning (RL) are able to make full use of the large amount of financial data with fewer model assumptions and to improve decisions in complex financial environments. This survey paper aims to review the recent developments and use of RL approaches in finance. We give an introduction to Markov decision processes, which is the setting for many of the commonly used RL approaches. Various algorithms are then introduced with a focus on value and policy based methods that do not require any model assumptions. Connections are made with neural networks to extend the framework to encompass deep RL algorithms. Our survey concludes by discussing the application of these RL algorithms in a variety of decision-making problems in finance, including optimal execution, portfolio optimization, option pricing and hedging, market making, smart order routing, and robo-advising.
Policy Gradient Methods Find the Nash Equilibrium in N-player General-sum Linear-quadratic Games
Jul 27, 2021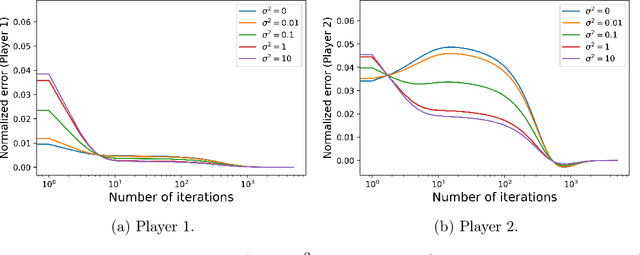
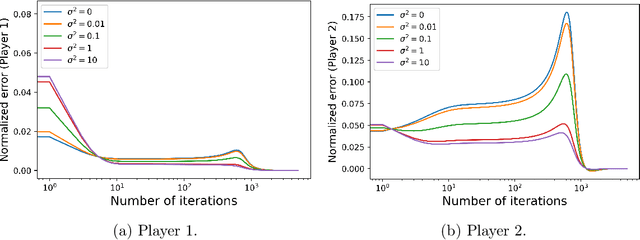
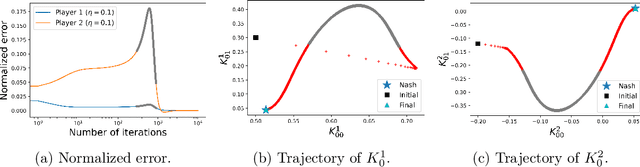
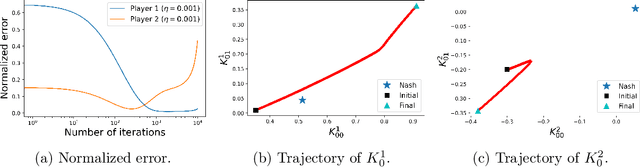
We consider a general-sum N-player linear-quadratic game with stochastic dynamics over a finite horizon and prove the global convergence of the natural policy gradient method to the Nash equilibrium. In order to prove the convergence of the method, we require a certain amount of noise in the system. We give a condition, essentially a lower bound on the covariance of the noise in terms of the model parameters, in order to guarantee convergence. We illustrate our results with numerical experiments to show that even in situations where the policy gradient method may not converge in the deterministic setting, the addition of noise leads to convergence.
Policy Gradient Methods for the Noisy Linear Quadratic Regulator over a Finite Horizon
Nov 20, 2020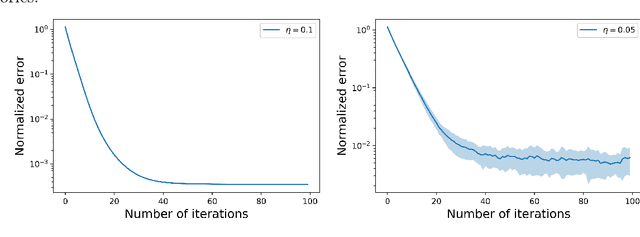

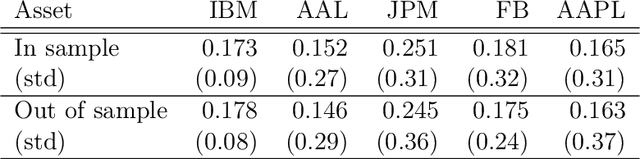
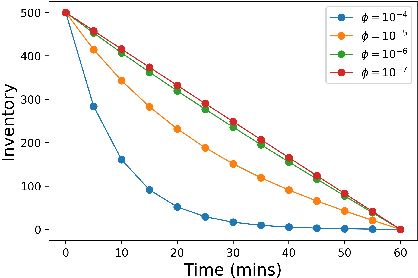
We explore reinforcement learning methods for finding the optimal policy in the linear quadratic regulator (LQR) problem. In particular, we consider the convergence of policy gradient methods in the setting of known and unknown parameters. We are able to produce a global linear convergence guarantee for this approach in the setting of finite time horizon and stochastic state dynamics under weak assumptions. The convergence of a projected policy gradient method is also established in order to handle problems with constraints. We illustrate the performance of the algorithm with two examples. The first example is the optimal liquidation of a holding in an asset. We show results for the case where we assume a model for the underlying dynamics and where we apply the method to the data directly. The empirical evidence suggests that the policy gradient method can learn the global optimal solution for a larger class of stochastic systems containing the LQR framework and that it is more robust with respect to model mis-specification when compared to a model-based approach. The second example is an LQR system in a higher dimensional setting with synthetic data.