 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork representations reveal structured uncertainty in music
Sep 17, 2025



Music, as a structured yet perceptually rich experience, can be modeled as a network to uncover how humans encode and process auditory information. While network-based representations of music are increasingly common, the impact of feature selection on structural properties and cognitive alignment remains underexplored. In this study, we evaluated eight network models, each constructed from symbolic representations of piano compositions using distinct combinations of pitch, octave, duration, and interval, designed to be representative of existing approaches in the literature. By comparing these models through topological metrics, entropy analysis, and divergence with respect to inferred cognitive representations, we assessed both their structural and perceptual efficiency. Our findings reveal that simpler, feature-specific models better match human perception, whereas complex, multidimensional representations introduce cognitive inefficiencies. These results support the view that humans rely on modular, parallel cognitive networks--an architecture consistent with theories of predictive processing and free energy minimization. Moreover, we find that musical networks are structurally organized to guide attention toward transitions that are both uncertain and inferable. The resulting structure concentrates uncertainty in a few frequently visited nodes, creating local entropy gradients that alternate between stable and unpredictable regions, thereby enabling the expressive dynamics of tension and release that define the musical experience. These findings show that network structures make the organization of uncertainty in music observable, offering new insight into how patterned flows of expectation shape perception, and open new directions for studying how musical structures evolve across genres, cultures, and historical periods through the lens of network science.
Early evidence of how LLMs outperform traditional systems on OCR/HTR tasks for historical records
Jan 20, 2025



We explore the ability of two LLMs -- GPT-4o and Claude Sonnet 3.5 -- to transcribe historical handwritten documents in a tabular format and compare their performance to traditional OCR/HTR systems: EasyOCR, Keras, Pytesseract, and TrOCR. Considering the tabular form of the data, two types of experiments are executed: one where the images are split line by line and the other where the entire scan is used as input. Based on CER and BLEU, we demonstrate that LLMs outperform the conventional OCR/HTR methods. Moreover, we also compare the evaluated CER and BLEU scores to human evaluations to better judge the outputs of whole-scan experiments and understand influential factors for CER and BLEU. Combining judgments from all the evaluation metrics, we conclude that two-shot GPT-4o for line-by-line images and two-shot Claude Sonnet 3.5 for whole-scan images yield the transcriptions of the historical records most similar to the ground truth.
Collaborative Filtering with Recurrent Neural Networks
Jan 03, 2017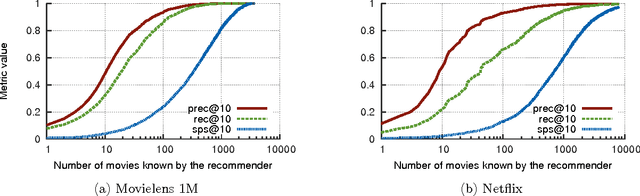
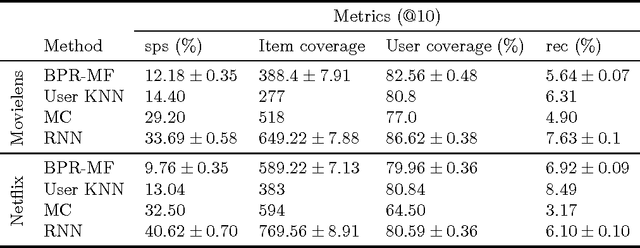
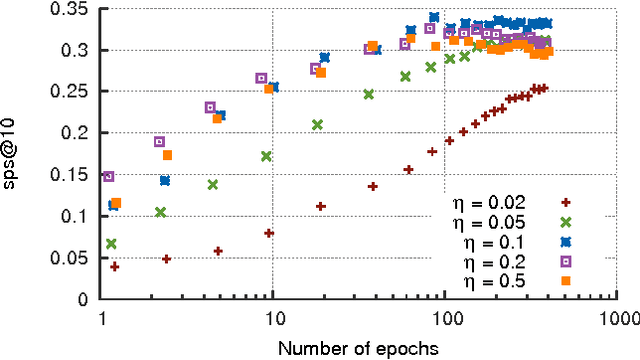
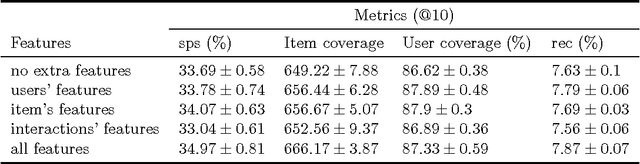
We show that collaborative filtering can be viewed as a sequence prediction problem, and that given this interpretation, recurrent neural networks offer very competitive approach. In particular we study how the long short-term memory (LSTM) can be applied to collaborative filtering, and how it compares to standard nearest neighbors and matrix factorization methods on movie recommendation. We show that the LSTM is competitive in all aspects, and largely outperforms other methods in terms of item coverage and short term predictions.