 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn "outside the box" solution for imbalanced data classification
Nov 16, 2019

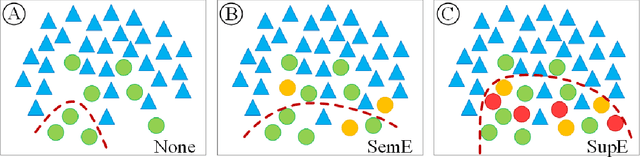
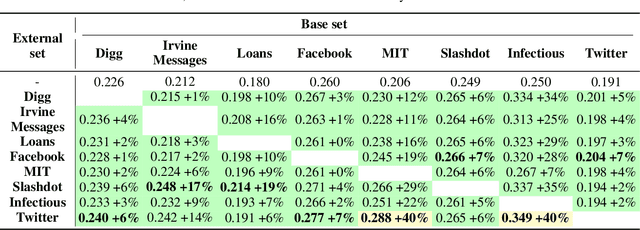
A common problem of the real-world data sets is the class imbalance, which can significantly affect the classification abilities of classifiers. Numerous methods have been proposed to cope with this problem; however, even state-of-the-art methods offer a limited improvement (if any) for data sets with critically under-represented minority classes. For such problematic cases, an "outside the box" solution is required. Therefore, we propose a novel technique, called enrichment, which uses the information (observations) from the external data set(s). We present three approaches to implement enrichment technique: (1) selecting observations randomly, (2) iteratively choosing observations that improve the classification result, (3) adding observations that help the classifier to determine the border between classes better. We then thoroughly analyze developed solutions on ten real-world data sets to experimentally validate their usefulness. On average, our best approach improves the classification quality by 27\%, and in the best case, by outstanding 66\%. We also compare our technique with the universally applicable state-of-the-art methods. We find that our technique surpasses the existing methods performing, on average, 21\% better. The advantage is especially noticeable for the smallest data sets, for which existing methods failed, while our solutions achieved the best results. Additionally, our technique applies to both the multi-class and binary classification tasks. It can also be combined with other techniques dealing with the class imbalance problem.