 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement with Overlapped-Frame Information Fusion and Causal Self-Attention
Jan 21, 2025For time-frequency (TF) domain speech enhancement (SE) methods, the overlap-and-add operation in the inverse TF transformation inevitably leads to an algorithmic delay equal to the window size. However, typical causal SE systems fail to utilize the future speech information within this inherent delay, thereby limiting SE performance. In this paper, we propose an overlapped-frame information fusion scheme. At each frame index, we construct several pseudo overlapped-frames, fuse them with the original speech frame, and then send the fused results to the SE model. Additionally, we introduce a causal time-frequency-channel attention (TFCA) block to boost the representation capability of the neural network. This block parallelly processes the intermediate feature maps through self-attention-based operations in the time, frequency, and channel dimensions. Experiments demonstrate the superiority of these improvements, and the proposed SE system outperforms the current advanced methods.
A Two-Stage Framework in Cross-Spectrum Domain for Real-Time Speech Enhancement
Jan 19, 2024Two-stage pipeline is popular in speech enhancement tasks due to its superiority over traditional single-stage methods. The current two-stage approaches usually enhance the magnitude spectrum in the first stage, and further modify the complex spectrum to suppress the residual noise and recover the speech phase in the second stage. The above whole process is performed in the short-time Fourier transform (STFT) spectrum domain. In this paper, we re-implement the above second sub-process in the short-time discrete cosine transform (STDCT) spectrum domain. The reason is that we have found STDCT performs greater noise suppression capability than STFT. Additionally, the implicit phase of STDCT ensures simpler and more efficient phase recovery, which is challenging and computationally expensive in the STFT-based methods. Therefore, we propose a novel two-stage framework called the STFT-STDCT spectrum fusion network (FDFNet) for speech enhancement in cross-spectrum domain. Experimental results demonstrate that the proposed FDFNet outperforms the previous two-stage methods and also exhibits superior performance compared to other advanced systems.
Magnitude-and-phase-aware Speech Enhancement with Parallel Sequence Modeling
Oct 11, 2023In speech enhancement (SE), phase estimation is important for perceptual quality, so many methods take clean speech's complex short-time Fourier transform (STFT) spectrum or the complex ideal ratio mask (cIRM) as the learning target. To predict these complex targets, the common solution is to design a complex neural network, or use a real network to separately predict the real and imaginary parts of the target. But in this paper, we propose to use a real network to estimate the magnitude mask and normalized cIRM, which not only avoids the significant increase of the model complexity caused by complex networks, but also shows better performance than previous phase estimation methods. Meanwhile, we devise a parallel sequence modeling (PSM) block to improve the RNN block in the convolutional recurrent network (CRN)-based SE model. We name our method as magnitude-and-phase-aware and PSM-based CRN (MPCRN). The experimental results illustrate that our MPCRN has superior SE performance.
VSANet: Real-time Speech Enhancement Based on Voice Activity Detection and Causal Spatial Attention
Oct 11, 2023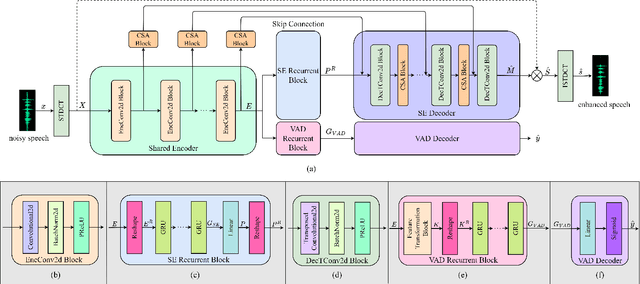
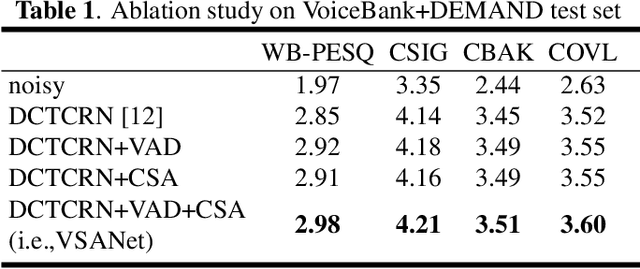

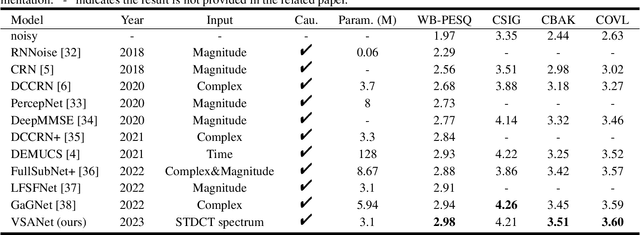
The deep learning-based speech enhancement (SE) methods always take the clean speech's waveform or time-frequency spectrum feature as the learning target, and train the deep neural network (DNN) by reducing the error loss between the DNN's output and the target. This is a conventional single-task learning paradigm, which has been proven to be effective, but we find that the multi-task learning framework can improve SE performance. Specifically, we design a framework containing a SE module and a voice activity detection (VAD) module, both of which share the same encoder, and the whole network is optimized by the weighted loss of the two modules. Moreover, we design a causal spatial attention (CSA) block to promote the representation capability of DNN. Combining the VAD aided multi-task learning framework and CSA block, our SE network is named VSANet. The experimental results prove the benefits of multi-task learning and the CSA block, which give VSANet an excellent SE performance.