 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSANet: Real-time Speech Enhancement Based on Voice Activity Detection and Causal Spatial Attention
Paper and Code
Oct 11, 2023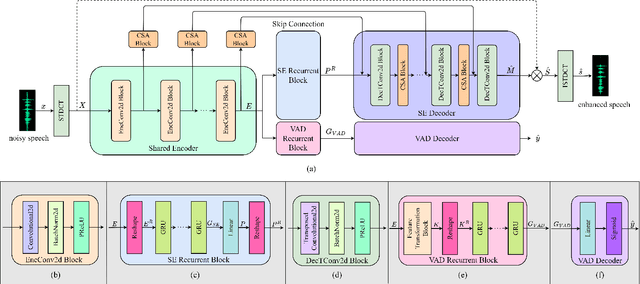
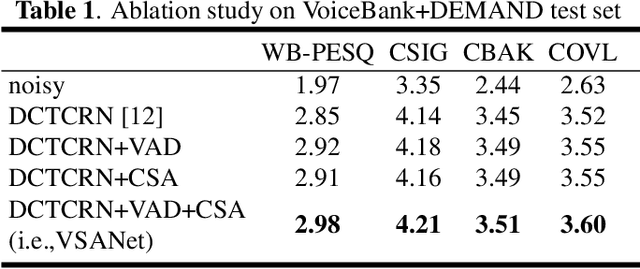

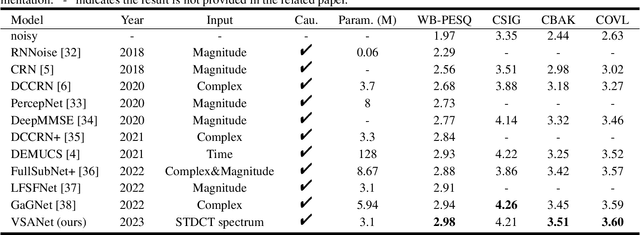
The deep learning-based speech enhancement (SE) methods always take the clean speech's waveform or time-frequency spectrum feature as the learning target, and train the deep neural network (DNN) by reducing the error loss between the DNN's output and the target. This is a conventional single-task learning paradigm, which has been proven to be effective, but we find that the multi-task learning framework can improve SE performance. Specifically, we design a framework containing a SE module and a voice activity detection (VAD) module, both of which share the same encoder, and the whole network is optimized by the weighted loss of the two modules. Moreover, we design a causal spatial attention (CSA) block to promote the representation capability of DNN. Combining the VAD aided multi-task learning framework and CSA block, our SE network is named VSANet. The experimental results prove the benefits of multi-task learning and the CSA block, which give VSANet an excellent SE performance.