 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Labels via Self-Taught On-the-Fly Meta Loss Rescaling
Dec 17, 2024



Correct labels are indispensable for training effective machine learning models. However, creating high-quality labels is expensive, and even professionally labeled data contains errors and ambiguities. Filtering and denoising can be applied to curate labeled data prior to training, at the cost of additional processing and loss of information. An alternative is on-the-fly sample reweighting during the training process to decrease the negative impact of incorrect or ambiguous labels, but this typically requires clean seed data. In this work we propose unsupervised on-the-fly meta loss rescaling to reweight training samples. Crucially, we rely only on features provided by the model being trained, to learn a rescaling function in real time without knowledge of the true clean data distribution. We achieve this via a novel meta learning setup that samples validation data for the meta update directly from the noisy training corpus by employing the rescaling function being trained. Our proposed method consistently improves performance across various NLP tasks with minimal computational overhead. Further, we are among the first to attempt on-the-fly training data reweighting on the challenging task of dialogue modeling, where noisy and ambiguous labels are common. Our strategy is robust in the face of noisy and clean data, handles class imbalance, and prevents overfitting to noisy labels. Our self-taught loss rescaling improves as the model trains, showing the ability to keep learning from the model's own signals. As training progresses, the impact of correctly labeled data is scaled up, while the impact of wrongly labeled data is suppressed.
Dialogue Ontology Relation Extraction via Constrained Chain-of-Thought Decoding
Aug 05, 2024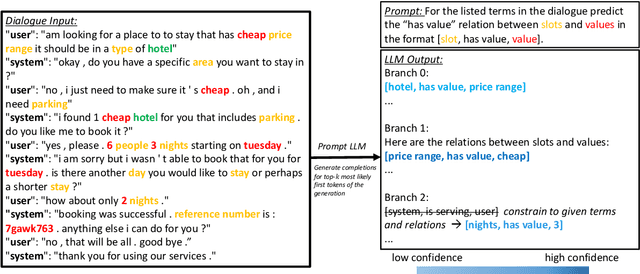

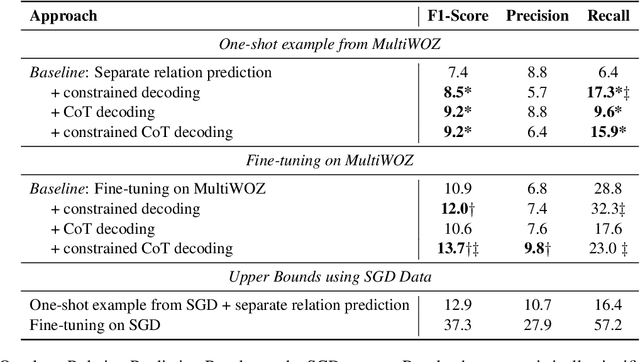
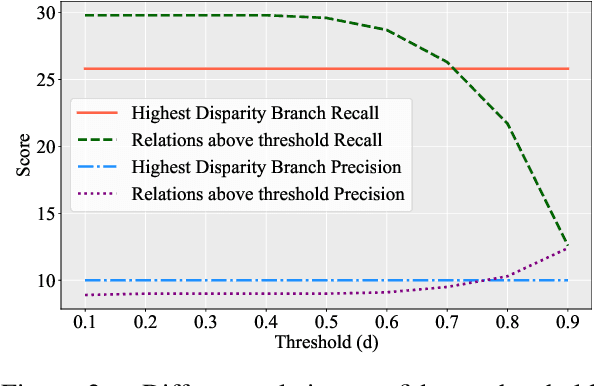
State-of-the-art task-oriented dialogue systems typically rely on task-specific ontologies for fulfilling user queries. The majority of task-oriented dialogue data, such as customer service recordings, comes without ontology and annotation. Such ontologies are normally built manually, limiting the application of specialised systems. Dialogue ontology construction is an approach for automating that process and typically consists of two steps: term extraction and relation extraction. In this work, we focus on relation extraction in a transfer learning set-up. To improve the generalisation, we propose an extension to the decoding mechanism of large language models. We adapt Chain-of-Thought (CoT) decoding, recently developed for reasoning problems, to generative relation extraction. Here, we generate multiple branches in the decoding space and select the relations based on a confidence threshold. By constraining the decoding to ontology terms and relations, we aim to decrease the risk of hallucination. We conduct extensive experimentation on two widely used datasets and find improvements in performance on target ontology for source fine-tuned and one-shot prompted large language models.
EmoUS: Simulating User Emotions in Task-Oriented Dialogues
Jun 02, 2023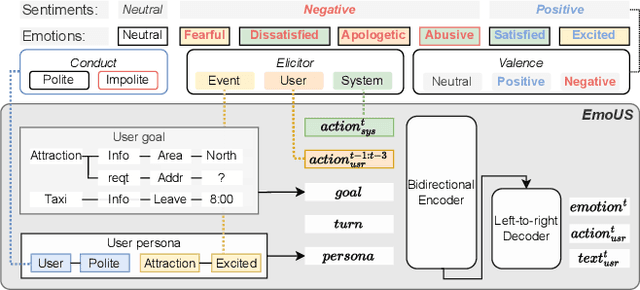
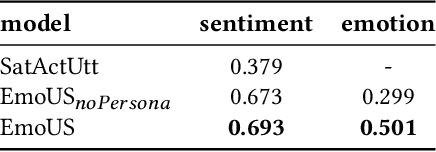
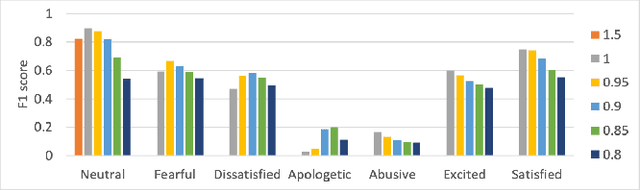

Existing user simulators (USs) for task-oriented dialogue systems only model user behaviour on semantic and natural language levels without considering the user persona and emotions. Optimising dialogue systems with generic user policies, which cannot model diverse user behaviour driven by different emotional states, may result in a high drop-off rate when deployed in the real world. Thus, we present EmoUS, a user simulator that learns to simulate user emotions alongside user behaviour. EmoUS generates user emotions, semantic actions, and natural language responses based on the user goal, the dialogue history, and the user persona. By analysing what kind of system behaviour elicits what kind of user emotions, we show that EmoUS can be used as a probe to evaluate a variety of dialogue systems and in particular their effect on the user's emotional state. Developing such methods is important in the age of large language model chat-bots and rising ethical concerns.
ChatGPT for Zero-shot Dialogue State Tracking: A Solution or an Opportunity?
Jun 02, 2023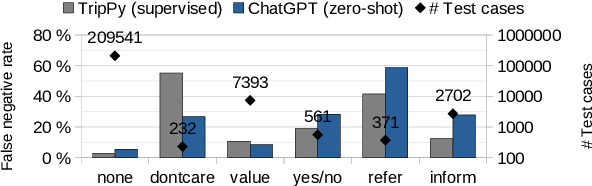
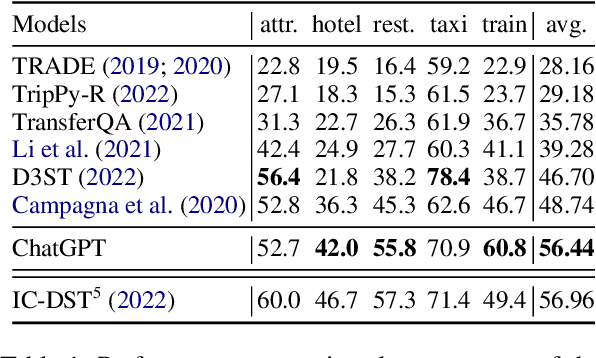

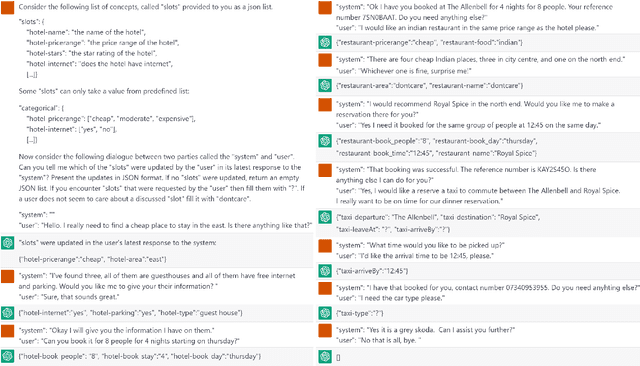
Recent research on dialogue state tracking (DST) focuses on methods that allow few- and zero-shot transfer to new domains or schemas. However, performance gains heavily depend on aggressive data augmentation and fine-tuning of ever larger language model based architectures. In contrast, general purpose language models, trained on large amounts of diverse data, hold the promise of solving any kind of task without task-specific training. We present preliminary experimental results on the ChatGPT research preview, showing that ChatGPT achieves state-of-the-art performance in zero-shot DST. Despite our findings, we argue that properties inherent to general purpose models limit their ability to replace specialized systems. We further theorize that the in-context learning capabilities of such models will likely become powerful tools to support the development of dedicated and dynamic dialogue state trackers.
Dialogue Evaluation with Offline Reinforcement Learning
Sep 02, 2022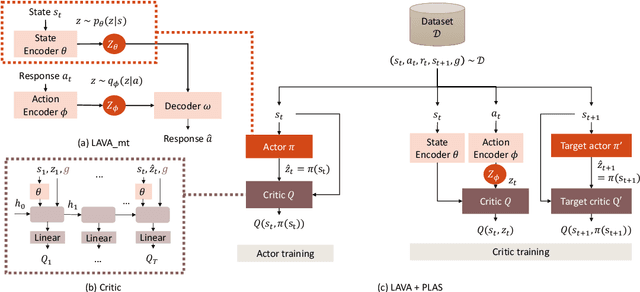
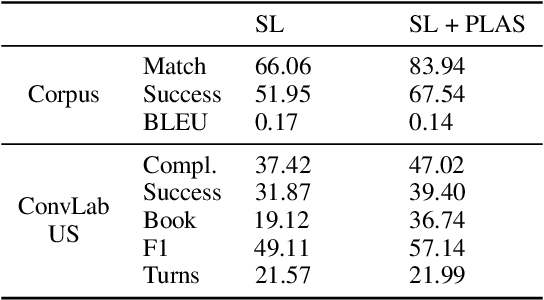
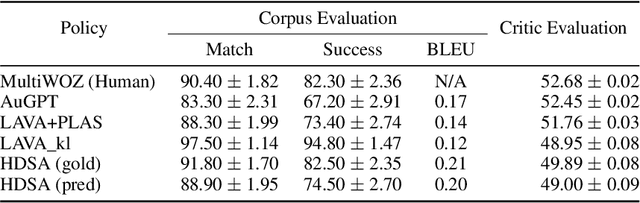

Task-oriented dialogue systems aim to fulfill user goals through natural language interactions. They are ideally evaluated with human users, which however is unattainable to do at every iteration of the development phase. Simulated users could be an alternative, however their development is nontrivial. Therefore, researchers resort to offline metrics on existing human-human corpora, which are more practical and easily reproducible. They are unfortunately limited in reflecting real performance of dialogue systems. BLEU for instance is poorly correlated with human judgment, and existing corpus-based metrics such as success rate overlook dialogue context mismatches. There is still a need for a reliable metric for task-oriented systems with good generalization and strong correlation with human judgements. In this paper, we propose the use of offline reinforcement learning for dialogue evaluation based on a static corpus. Such an evaluator is typically called a critic and utilized for policy optimization. We go one step further and show that offline RL critics can be trained on a static corpus for any dialogue system as external evaluators, allowing dialogue performance comparisons across various types of systems. This approach has the benefit of being corpus- and model-independent, while attaining strong correlation with human judgements, which we confirm via an interactive user trial.
GenTUS: Simulating User Behaviour and Language in Task-oriented Dialogues with Generative Transformers
Aug 23, 2022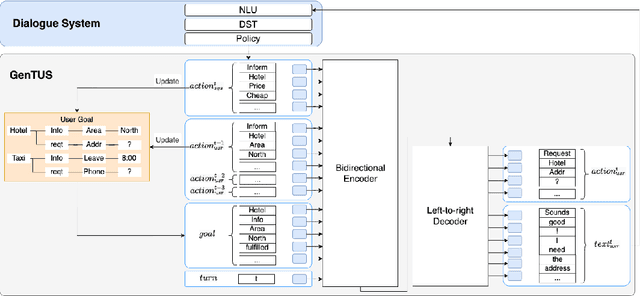
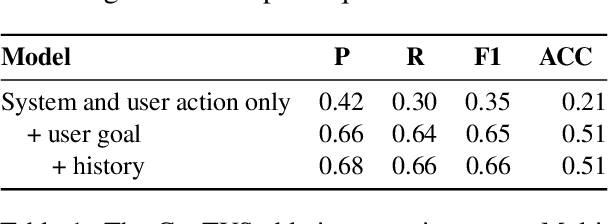
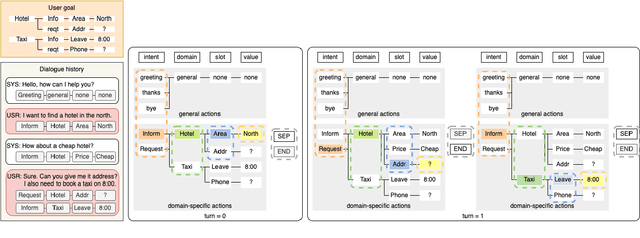

User simulators (USs) are commonly used to train task-oriented dialogue systems (DSs) via reinforcement learning. The interactions often take place on semantic level for efficiency, but there is still a gap from semantic actions to natural language, which causes a mismatch between training and deployment environment. Incorporating a natural language generation (NLG) module with USs during training can partly deal with this problem. However, since the policy and NLG of USs are optimised separately, these simulated user utterances may not be natural enough in a given context. In this work, we propose a generative transformer-based user simulator (GenTUS). GenTUS consists of an encoder-decoder structure, which means it can optimise both the user policy and natural language generation jointly. GenTUS generates both semantic actions and natural language utterances, preserving interpretability and enhancing language variation. In addition, by representing the inputs and outputs as word sequences and by using a large pre-trained language model we can achieve generalisability in feature representation. We evaluate GenTUS with automatic metrics and human evaluation. Our results show that GenTUS generates more natural language and is able to transfer to an unseen ontology in a zero-shot fashion. In addition, its behaviour can be further shaped with reinforcement learning opening the door to training specialised user simulators.
Dynamic Dialogue Policy Transformer for Continual Reinforcement Learning
Apr 12, 2022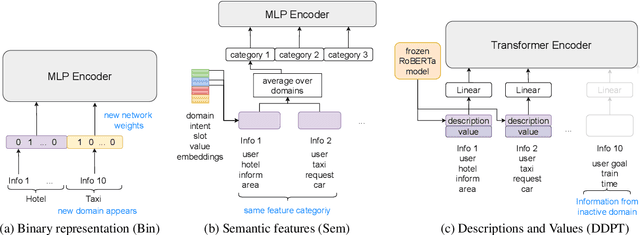
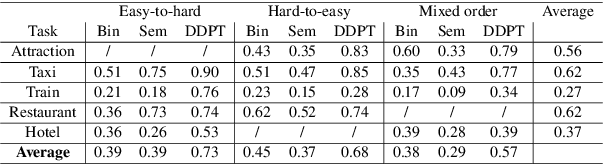
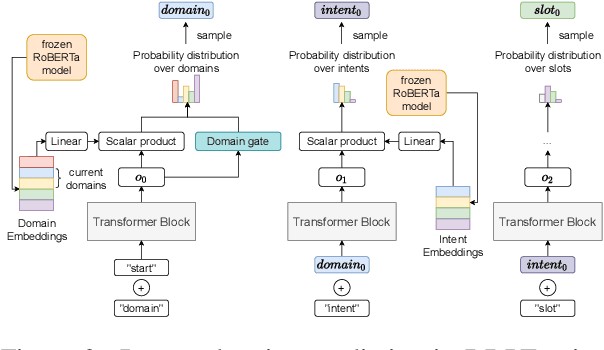
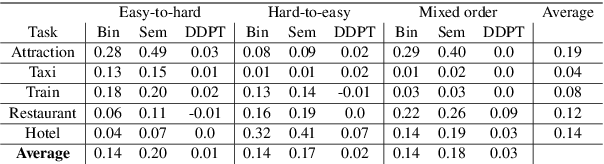
Continual learning is one of the key components of human learning and a necessary requirement of artificial intelligence. As dialogue can potentially span infinitely many topics and tasks, a task-oriented dialogue system must have the capability to continually learn, dynamically adapting to new challenges while preserving the knowledge it already acquired. Despite the importance, continual reinforcement learning of the dialogue policy has remained largely unaddressed. The lack of a framework with training protocols, baseline models and suitable metrics, has so far hindered research in this direction. In this work we fill precisely this gap, enabling research in dialogue policy optimisation to go from static to dynamic learning. We provide a continual learning algorithm, baseline architectures and metrics for assessing continual learning models. Moreover, we propose the dynamic dialogue policy transformer (DDPT), a novel dynamic architecture that can integrate new knowledge seamlessly, is capable of handling large state spaces and obtains significant zero-shot performance when being exposed to unseen domains, without any growth in network parameter size.
Robust Dialogue State Tracking with Weak Supervision and Sparse Data
Feb 07, 2022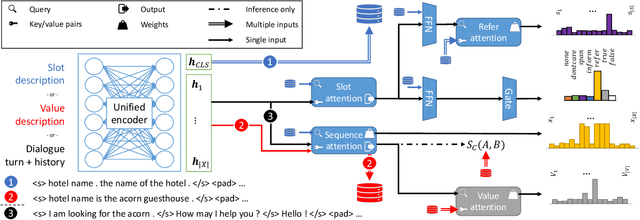

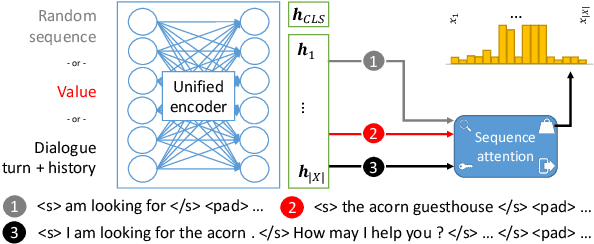
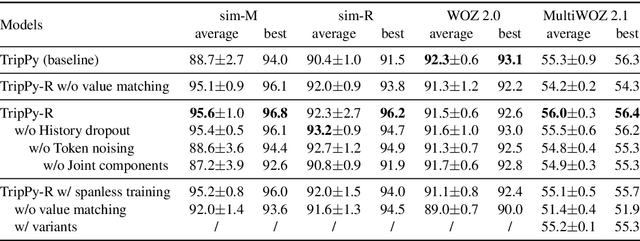
Generalising dialogue state tracking (DST) to new data is especially challenging due to the strong reliance on abundant and fine-grained supervision during training. Sample sparsity, distributional shift and the occurrence of new concepts and topics frequently lead to severe performance degradation during inference. In this paper we propose a training strategy to build extractive DST models without the need for fine-grained manual span labels. Two novel input-level dropout methods mitigate the negative impact of sample sparsity. We propose a new model architecture with a unified encoder that supports value as well as slot independence by leveraging the attention mechanism. We combine the strengths of triple copy strategy DST and value matching to benefit from complementary predictions without violating the principle of ontology independence. Our experiments demonstrate that an extractive DST model can be trained without manual span labels. Our architecture and training strategies improve robustness towards sample sparsity, new concepts and topics, leading to state-of-the-art performance on a range of benchmarks. We further highlight our model's ability to effectively learn from non-dialogue data.
Out-of-Task Training for Dialog State Tracking Models
Nov 18, 2020
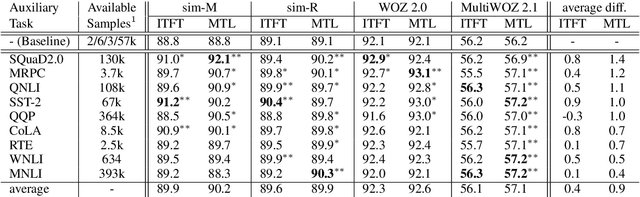
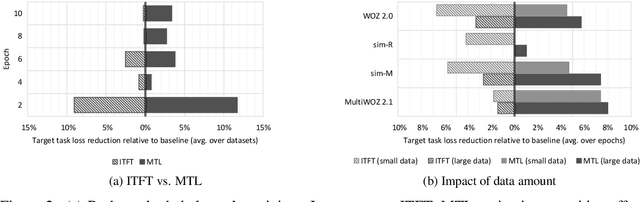

Dialog state tracking (DST) suffers from severe data sparsity. While many natural language processing (NLP) tasks benefit from transfer learning and multi-task learning, in dialog these methods are limited by the amount of available data and by the specificity of dialog applications. In this work, we successfully utilize non-dialog data from unrelated NLP tasks to train dialog state trackers. This opens the door to the abundance of unrelated NLP corpora to mitigate the data sparsity issue inherent to DST.
Knowing What You Know: Calibrating Dialogue Belief State Distributions via Ensembles
Oct 06, 2020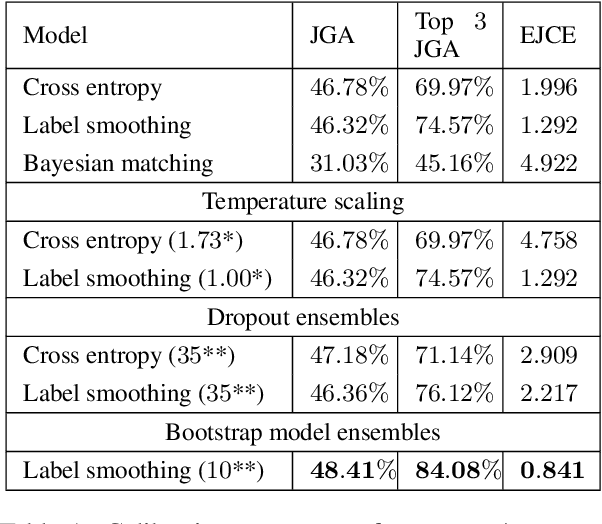
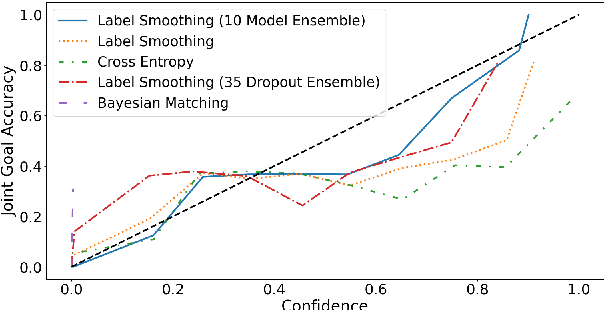


The ability to accurately track what happens during a conversation is essential for the performance of a dialogue system. Current state-of-the-art multi-domain dialogue state trackers achieve just over 55% accuracy on the current go-to benchmark, which means that in almost every second dialogue turn they place full confidence in an incorrect dialogue state. Belief trackers, on the other hand, maintain a distribution over possible dialogue states. However, they lack in performance compared to dialogue state trackers, and do not produce well calibrated distributions. In this work we present state-of-the-art performance in calibration for multi-domain dialogue belief trackers using a calibrated ensemble of models. Our resulting dialogue belief tracker also outperforms previous dialogue belief tracking models in terms of accuracy.