 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityscape-Adverse: Benchmarking Robustness of Semantic Segmentation with Realistic Scene Modifications via Diffusion-Based Image Editing
Nov 01, 2024


Recent advancements in generative AI, particularly diffusion-based image editing, have enabled the transformation of images into highly realistic scenes using only text instructions. This technology offers significant potential for generating diverse synthetic datasets to evaluate model robustness. In this paper, we introduce Cityscape-Adverse, a benchmark that employs diffusion-based image editing to simulate eight adverse conditions, including variations in weather, lighting, and seasons, while preserving the original semantic labels. We evaluate the reliability of diffusion-based models in generating realistic scene modifications and assess the performance of state-of-the-art CNN and Transformer-based semantic segmentation models under these challenging conditions. Additionally, we analyze which modifications have the greatest impact on model performance and explore how training on synthetic datasets can improve robustness in real-world adverse scenarios. Our results demonstrate that all tested models, particularly CNN-based architectures, experienced significant performance degradation under extreme conditions, while Transformer-based models exhibited greater resilience. We verify that models trained on Cityscape-Adverse show significantly enhanced resilience when applied to unseen domains. Code and datasets will be released at https://github.com/naufalso/cityscape-adverse.
Adversarial Manhole: Challenging Monocular Depth Estimation and Semantic Segmentation Models with Patch Attack
Aug 27, 2024
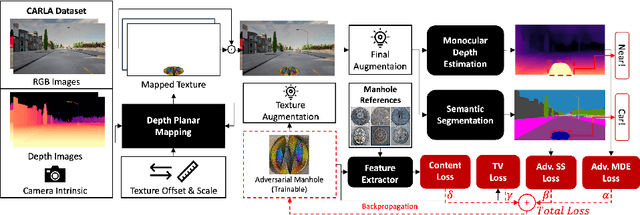
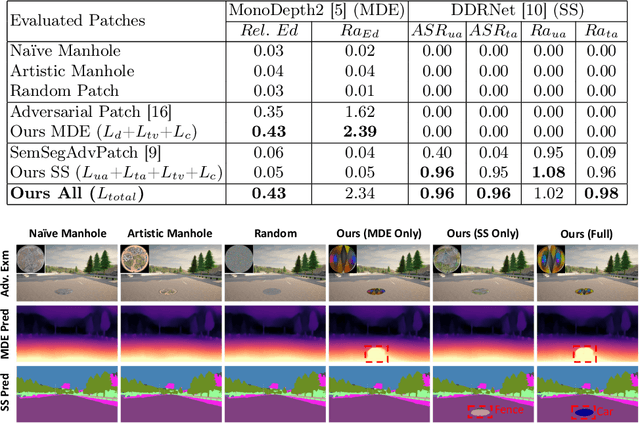
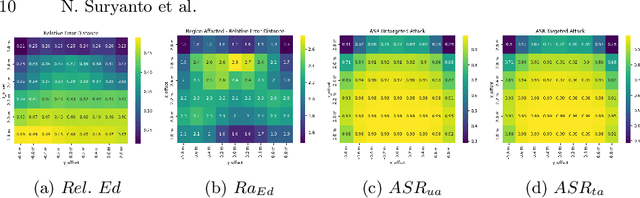
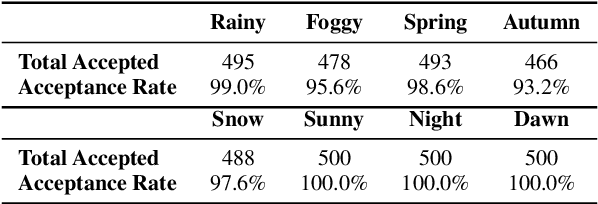
Monocular depth estimation (MDE) and semantic segmentation (SS) are crucial for the navigation and environmental interpretation of many autonomous driving systems. However, their vulnerability to practical adversarial attacks is a significant concern. This paper presents a novel adversarial attack using practical patches that mimic manhole covers to deceive MDE and SS models. The goal is to cause these systems to misinterpret scenes, leading to false detections of near obstacles or non-passable objects. We use Depth Planar Mapping to precisely position these patches on road surfaces, enhancing the attack's effectiveness. Our experiments show that these adversarial patches cause a 43% relative error in MDE and achieve a 96% attack success rate in SS. These patches create affected error regions over twice their size in MDE and approximately equal to their size in SS. Our studies also confirm the patch's effectiveness in physical simulations, the adaptability of the patches across different target models, and the effectiveness of our proposed modules, highlighting their practical implications.
CIPHER: Cybersecurity Intelligent Penetration-testing Helper for Ethical Researcher
Aug 21, 2024



Penetration testing, a critical component of cybersecurity, typically requires extensive time and effort to find vulnerabilities. Beginners in this field often benefit from collaborative approaches with the community or experts. To address this, we develop CIPHER (Cybersecurity Intelligent Penetration-testing Helper for Ethical Researchers), a large language model specifically trained to assist in penetration testing tasks. We trained CIPHER using over 300 high-quality write-ups of vulnerable machines, hacking techniques, and documentation of open-source penetration testing tools. Additionally, we introduced the Findings, Action, Reasoning, and Results (FARR) Flow augmentation, a novel method to augment penetration testing write-ups to establish a fully automated pentesting simulation benchmark tailored for large language models. This approach fills a significant gap in traditional cybersecurity Q\&A benchmarks and provides a realistic and rigorous standard for evaluating AI's technical knowledge, reasoning capabilities, and practical utility in dynamic penetration testing scenarios. In our assessments, CIPHER achieved the best overall performance in providing accurate suggestion responses compared to other open-source penetration testing models of similar size and even larger state-of-the-art models like Llama 3 70B and Qwen1.5 72B Chat, particularly on insane difficulty machine setups. This demonstrates that the current capabilities of general LLMs are insufficient for effectively guiding users through the penetration testing process. We also discuss the potential for improvement through scaling and the development of better benchmarks using FARR Flow augmentation results. Our benchmark will be released publicly at https://github.com/ibndias/CIPHER.
ACTIVE: Towards Highly Transferable 3D Physical Camouflage for Universal and Robust Vehicle Evasion
Aug 16, 2023



Adversarial camouflage has garnered attention for its ability to attack object detectors from any viewpoint by covering the entire object's surface. However, universality and robustness in existing methods often fall short as the transferability aspect is often overlooked, thus restricting their application only to a specific target with limited performance. To address these challenges, we present Adversarial Camouflage for Transferable and Intensive Vehicle Evasion (ACTIVE), a state-of-the-art physical camouflage attack framework designed to generate universal and robust adversarial camouflage capable of concealing any 3D vehicle from detectors. Our framework incorporates innovative techniques to enhance universality and robustness, including a refined texture rendering that enables common texture application to different vehicles without being constrained to a specific texture map, a novel stealth loss that renders the vehicle undetectable, and a smooth and camouflage loss to enhance the naturalness of the adversarial camouflage. Our extensive experiments on 15 different models show that ACTIVE consistently outperforms existing works on various public detectors, including the latest YOLOv7. Notably, our universality evaluations reveal promising transferability to other vehicle classes, tasks (segmentation models), and the real world, not just other vehicles.
DTA: Physical Camouflage Attacks using Differentiable Transformation Network
Mar 18, 2022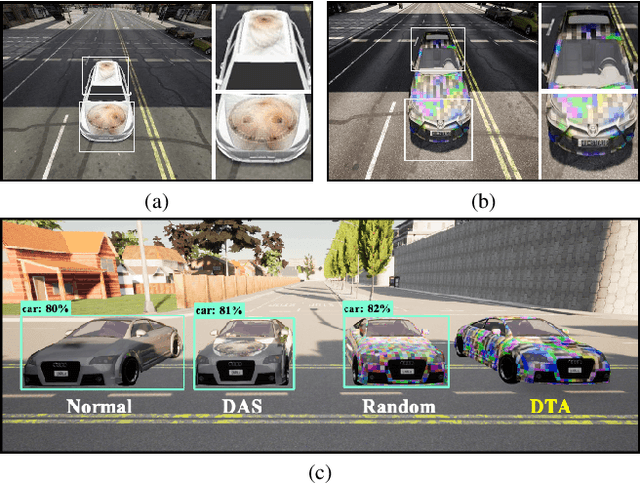
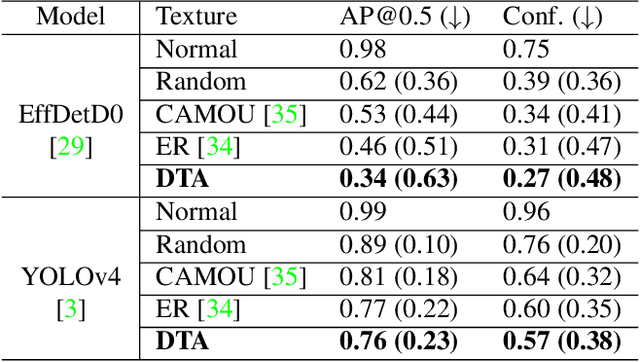
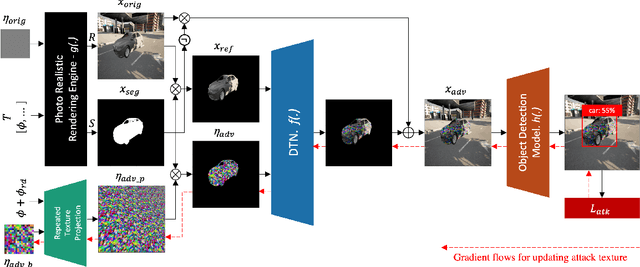
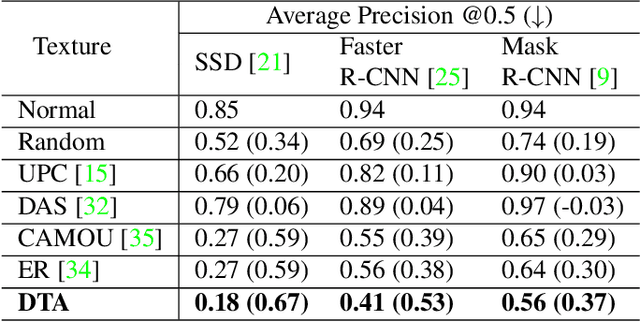
To perform adversarial attacks in the physical world, many studies have proposed adversarial camouflage, a method to hide a target object by applying camouflage patterns on 3D object surfaces. For obtaining optimal physical adversarial camouflage, previous studies have utilized the so-called neural renderer, as it supports differentiability. However, existing neural renderers cannot fully represent various real-world transformations due to a lack of control of scene parameters compared to the legacy photo-realistic renderers. In this paper, we propose the Differentiable Transformation Attack (DTA), a framework for generating a robust physical adversarial pattern on a target object to camouflage it against object detection models with a wide range of transformations. It utilizes our novel Differentiable Transformation Network (DTN), which learns the expected transformation of a rendered object when the texture is changed while preserving the original properties of the target object. Using our attack framework, an adversary can gain both the advantages of the legacy photo-realistic renderers including various physical-world transformations and the benefit of white-box access by offering differentiability. Our experiments show that our camouflaged 3D vehicles can successfully evade state-of-the-art object detection models in the photo-realistic environment (i.e., CARLA on Unreal Engine). Furthermore, our demonstration on a scaled Tesla Model 3 proves the applicability and transferability of our method to the real world.