 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Self-Supervised Algorithms for Fine-Grained Birdsong Analysis
Nov 15, 2025Many bioacoustics, neuroscience, and linguistics research utilize birdsongs as proxy models to acquire knowledge in diverse areas. Developing models generally requires precisely annotated data at the level of syllables. Hence, automated and data-efficient methods that reduce annotation costs are in demand. This work presents a lightweight, yet performant neural network architecture for birdsong annotation called Residual-MLP-RNN. Then, it presents a robust three-stage training pipeline for developing reliable deep birdsong syllable detectors with minimal expert labor. The first stage is self-supervised learning from unlabeled data. Two of the most successful pretraining paradigms are explored, namely, masked prediction and online clustering. The second stage is supervised training with effective data augmentations to create a robust model for frame-level syllable detection. The third stage is semi-supervised post-training, which leverages the unlabeled data again. However, unlike the initial phase, this time it is aligned with the downstream task. The performance of this data-efficient approach is demonstrated for the complex song of the Canary in extreme label-scarcity scenarios. Canary has one of the most difficult songs to annotate, which implicitly validates the method for other birds. Finally, the potential of self-supervised embeddings is assessed for linear probing and unsupervised birdsong analysis.
Comparison of self-supervised in-domain and supervised out-domain transfer learning for bird species recognition
Apr 26, 2024

Transferring the weights of a pre-trained model to assist another task has become a crucial part of modern deep learning, particularly in data-scarce scenarios. Pre-training refers to the initial step of training models outside the current task of interest, typically on another dataset. It can be done via supervised models using human-annotated datasets or self-supervised models trained on unlabeled datasets. In both cases, many pre-trained models are available to fine-tune for the task of interest. Interestingly, research has shown that pre-trained models from ImageNet can be helpful for audio tasks despite being trained on image datasets. Hence, it's unclear whether in-domain models would be advantageous compared to competent out-domain models, such as convolutional neural networks from ImageNet. Our experiments will demonstrate the usefulness of in-domain models and datasets for bird species recognition by leveraging VICReg, a recent and powerful self-supervised method.
An Efficient Method for the Classification of Croplands in Scarce-Label Regions
Mar 17, 2021

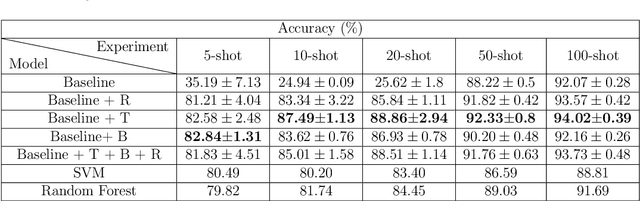
Two of the main challenges for cropland classification by satellite time-series images are insufficient ground-truth data and inaccessibility of high-quality hyperspectral images for under-developed areas. Unlabeled medium-resolution satellite images are abundant, but how to benefit from them is an open question. We will show how to leverage their potential for cropland classification using self-supervised tasks. Self-supervision is an approach where we provide simple training signals for the samples, which are apparent from the data's structure. Hence, they are cheap to acquire and explain a simple concept about the data. We introduce three self-supervised tasks for cropland classification. They reduce epistemic uncertainty, and the resulting model shows superior accuracy in a wide range of settings compared to SVM and Random Forest. Subsequently, we use the self-supervised tasks to perform unsupervised domain adaptation and benefit from the labeled samples in other regions. It is crucial to know what information to transfer to avoid degrading the performance. We show how to automate the information selection and transfer process in cropland classification even when the source and target areas have a very different feature distribution. We improved the model by about 24% compared to a baseline architecture without any labeled sample in the target domain. Our method is amenable to gradual improvement, works with medium-resolution satellite images, and does not require complicated models. Code and data are available.