 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Method for the Classification of Croplands in Scarce-Label Regions
Paper and Code


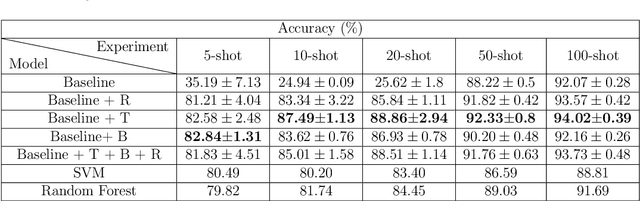
Two of the main challenges for cropland classification by satellite time-series images are insufficient ground-truth data and inaccessibility of high-quality hyperspectral images for under-developed areas. Unlabeled medium-resolution satellite images are abundant, but how to benefit from them is an open question. We will show how to leverage their potential for cropland classification using self-supervised tasks. Self-supervision is an approach where we provide simple training signals for the samples, which are apparent from the data's structure. Hence, they are cheap to acquire and explain a simple concept about the data. We introduce three self-supervised tasks for cropland classification. They reduce epistemic uncertainty, and the resulting model shows superior accuracy in a wide range of settings compared to SVM and Random Forest. Subsequently, we use the self-supervised tasks to perform unsupervised domain adaptation and benefit from the labeled samples in other regions. It is crucial to know what information to transfer to avoid degrading the performance. We show how to automate the information selection and transfer process in cropland classification even when the source and target areas have a very different feature distribution. We improved the model by about 24% compared to a baseline architecture without any labeled sample in the target domain. Our method is amenable to gradual improvement, works with medium-resolution satellite images, and does not require complicated models. Code and data are available.