 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn depth prediction for autonomous driving using self-supervised learning
Mar 10, 2024Perception of the environment is a critical component for enabling autonomous driving. It provides the vehicle with the ability to comprehend its surroundings and make informed decisions. Depth prediction plays a pivotal role in this process, as it helps the understanding of the geometry and motion of the environment. This thesis focuses on the challenge of depth prediction using monocular self-supervised learning techniques. The problem is approached from a broader perspective first, exploring conditional generative adversarial networks (cGANs) as a potential technique to achieve better generalization was performed. In doing so, a fundamental contribution to the conditional GANs, the acontrario cGAN was proposed. The second contribution entails a single image-to-depth self-supervised method, proposing a solution for the rigid-scene assumption using a novel transformer-based method that outputs a pose for each dynamic object. The third significant aspect involves the introduction of a video-to-depth map forecasting approach. This method serves as an extension of self-supervised techniques to predict future depths. This involves the creation of a novel transformer model capable of predicting the future depth of a given scene. Moreover, the various limitations of the aforementioned methods were addressed and a video-to-video depth maps model was proposed. This model leverages the spatio-temporal consistency of the input and output sequence to predict a more accurate depth sequence output. These methods have significant applications in autonomous driving (AD) and advanced driver assistance systems (ADAS).
STDepthFormer: Predicting Spatio-temporal Depth from Video with a Self-supervised Transformer Model
Mar 02, 2023In this paper, a self-supervised model that simultaneously predicts a sequence of future frames from video-input with a novel spatial-temporal attention (ST) network is proposed. The ST transformer network allows constraining both temporal consistency across future frames whilst constraining consistency across spatial objects in the image at different scales. This was not the case in prior works for depth prediction, which focused on predicting a single frame as output. The proposed model leverages prior scene knowledge such as object shape and texture similar to single-image depth inference methods, whilst also constraining the motion and geometry from a sequence of input images. Apart from the transformer architecture, one of the main contributions with respect to prior works lies in the objective function that enforces spatio-temporal consistency across a sequence of output frames rather than a single output frame. As will be shown, this results in more accurate and robust depth sequence forecasting. The model achieves highly accurate depth forecasting results that outperform existing baselines on the KITTI benchmark. Extensive ablation studies were performed to assess the effectiveness of the proposed techniques. One remarkable result of the proposed model is that it is implicitly capable of forecasting the motion of objects in the scene, rather than requiring complex models involving multi-object detection, segmentation and tracking.
Forecasting of depth and ego-motion with transformers and self-supervision
Jun 15, 2022
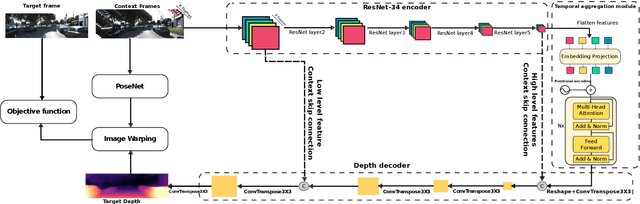
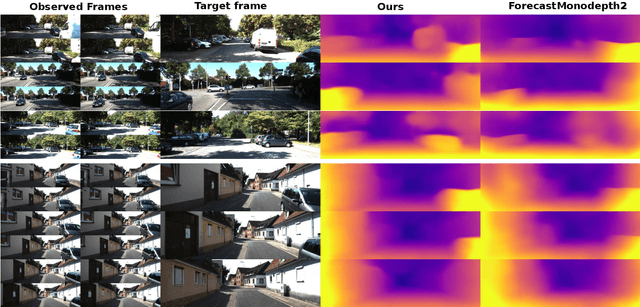
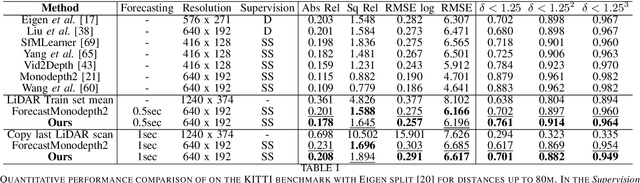
This paper addresses the problem of end-to-end self-supervised forecasting of depth and ego motion. Given a sequence of raw images, the aim is to forecast both the geometry and ego-motion using a self supervised photometric loss. The architecture is designed using both convolution and transformer modules. This leverages the benefits of both modules: Inductive bias of CNN, and the multi-head attention of transformers, thus enabling a rich spatio-temporal representation that enables accurate depth forecasting. Prior work attempts to solve this problem using multi-modal input/output with supervised ground-truth data which is not practical since a large annotated dataset is required. Alternatively to prior methods, this paper forecasts depth and ego motion using only self-supervised raw images as input. The approach performs significantly well on the KITTI dataset benchmark with several performance criteria being even comparable to prior non-forecasting self-supervised monocular depth inference methods.