 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDepthFormer: Predicting Spatio-temporal Depth from Video with a Self-supervised Transformer Model
Mar 02, 2023In this paper, a self-supervised model that simultaneously predicts a sequence of future frames from video-input with a novel spatial-temporal attention (ST) network is proposed. The ST transformer network allows constraining both temporal consistency across future frames whilst constraining consistency across spatial objects in the image at different scales. This was not the case in prior works for depth prediction, which focused on predicting a single frame as output. The proposed model leverages prior scene knowledge such as object shape and texture similar to single-image depth inference methods, whilst also constraining the motion and geometry from a sequence of input images. Apart from the transformer architecture, one of the main contributions with respect to prior works lies in the objective function that enforces spatio-temporal consistency across a sequence of output frames rather than a single output frame. As will be shown, this results in more accurate and robust depth sequence forecasting. The model achieves highly accurate depth forecasting results that outperform existing baselines on the KITTI benchmark. Extensive ablation studies were performed to assess the effectiveness of the proposed techniques. One remarkable result of the proposed model is that it is implicitly capable of forecasting the motion of objects in the scene, rather than requiring complex models involving multi-object detection, segmentation and tracking.
Forecasting of depth and ego-motion with transformers and self-supervision
Jun 15, 2022
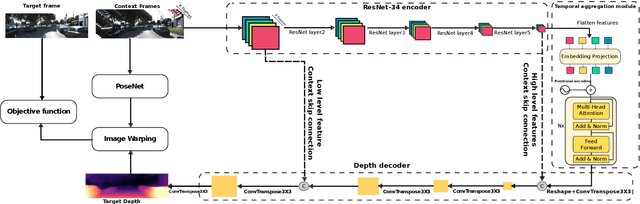
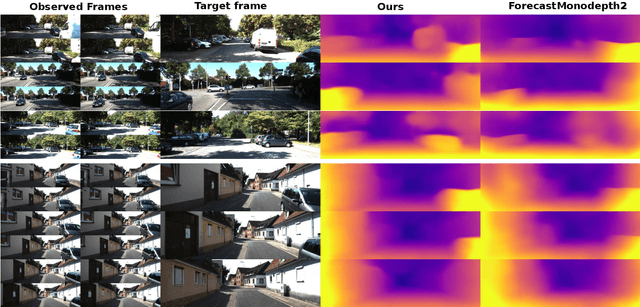
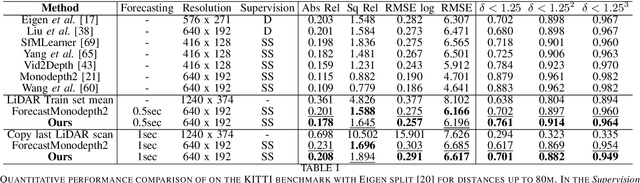
This paper addresses the problem of end-to-end self-supervised forecasting of depth and ego motion. Given a sequence of raw images, the aim is to forecast both the geometry and ego-motion using a self supervised photometric loss. The architecture is designed using both convolution and transformer modules. This leverages the benefits of both modules: Inductive bias of CNN, and the multi-head attention of transformers, thus enabling a rich spatio-temporal representation that enables accurate depth forecasting. Prior work attempts to solve this problem using multi-modal input/output with supervised ground-truth data which is not practical since a large annotated dataset is required. Alternatively to prior methods, this paper forecasts depth and ego motion using only self-supervised raw images as input. The approach performs significantly well on the KITTI dataset benchmark with several performance criteria being even comparable to prior non-forecasting self-supervised monocular depth inference methods.
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022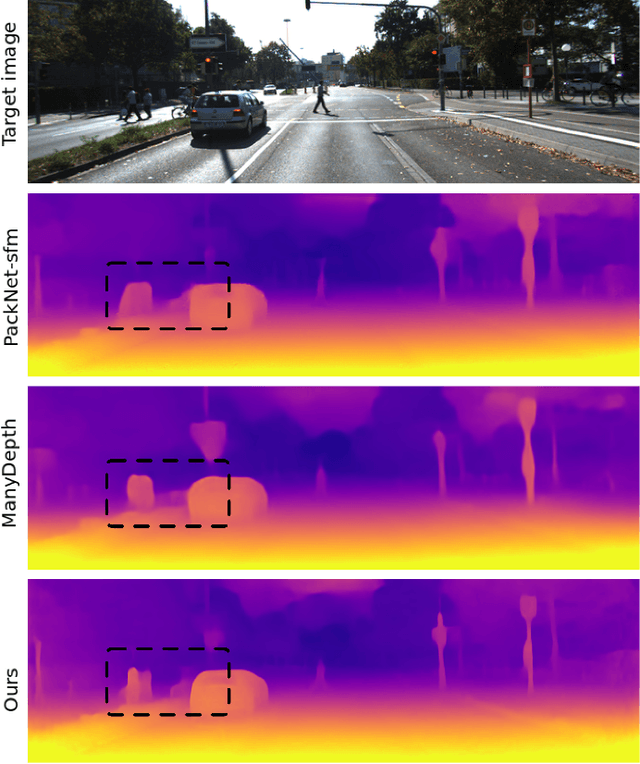
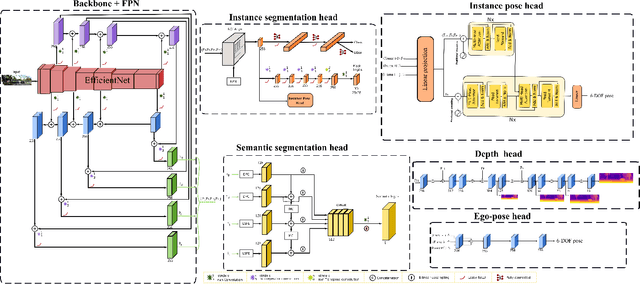
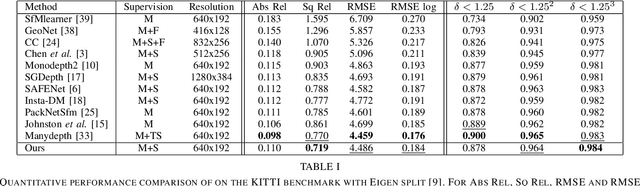
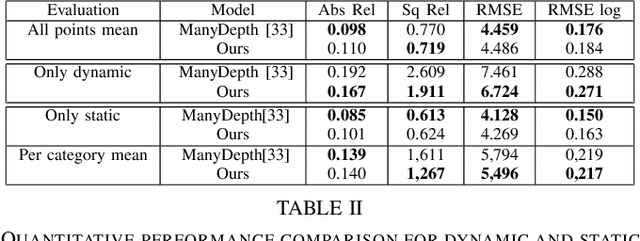
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.
Are conditional GANs explicitly conditional?
Jun 28, 2021
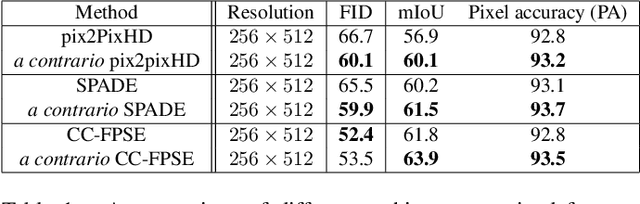
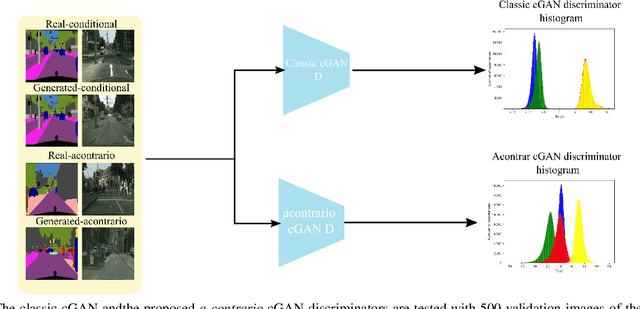

This paper proposes two important contributions for conditional Generative Adversarial Networks (cGANs) to improve the wide variety of applications that exploit this architecture. The first main contribution is an analysis of cGANs to show that they are not explicitly conditional. In particular, it will be shown that the discriminator and subsequently the cGAN does not automatically learn the conditionality between inputs. The second contribution is a new method, called acontrario, that explicitly models conditionality for both parts of the adversarial architecture via a novel acontrario loss that involves training the discriminator to learn unconditional (adverse) examples. This leads to a novel type of data augmentation approach for GANs (acontrario learning) which allows to restrict the search space of the generator to conditional outputs using adverse examples. Extensive experimentation is carried out to evaluate the conditionality of the discriminator by proposing a probability distribution analysis. Comparisons with the cGAN architecture for different applications show significant improvements in performance on well known datasets including, semantic image synthesis, image segmentation and monocular depth prediction using different metrics including Fr\'echet Inception Distance(FID), mean Intersection over Union (mIoU), Root Mean Square Error log (RMSE log) and Number of statistically-Different Bins (NDB)