 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDPL-PFOD2: A New Large-Scale Dataset for Printed Farsi Optical Character Recognition
Dec 02, 2023Optical Character Recognition is a technique that converts document images into searchable and editable text, making it a valuable tool for processing scanned documents. While the Farsi language stands as a prominent and official language in Asia, efforts to develop efficient methods for recognizing Farsi printed text have been relatively limited. This is primarily attributed to the languages distinctive features, such as cursive form, the resemblance between certain alphabet characters, and the presence of numerous diacritics and dot placement. On the other hand, given the substantial training sample requirements of deep-based architectures for effective performance, the development of such datasets holds paramount significance. In light of these concerns, this paper aims to present a novel large-scale dataset, IDPL-PFOD2, tailored for Farsi printed text recognition. The dataset comprises 2003541 images featuring a wide variety of fonts, styles, and sizes. This dataset is an extension of the previously introduced IDPL-PFOD dataset, offering a substantial increase in both volume and diversity. Furthermore, the datasets effectiveness is assessed through the utilization of both CRNN-based and Vision Transformer architectures. The CRNN-based model achieves a baseline accuracy rate of 78.49% and a normalized edit distance of 97.72%, while the Vision Transformer architecture attains an accuracy of 81.32% and a normalized edit distance of 98.74%.
NPC: Neighbors Progressive Competition Algorithm for Classification of Imbalanced Data Sets
Nov 29, 2017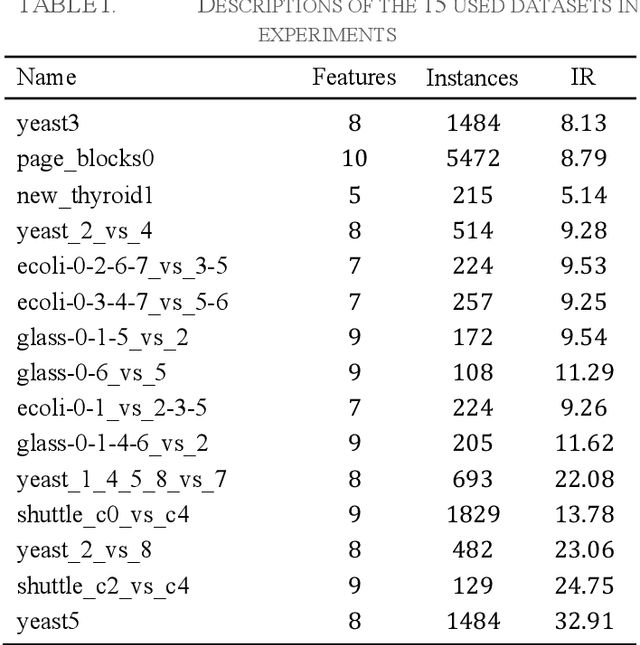

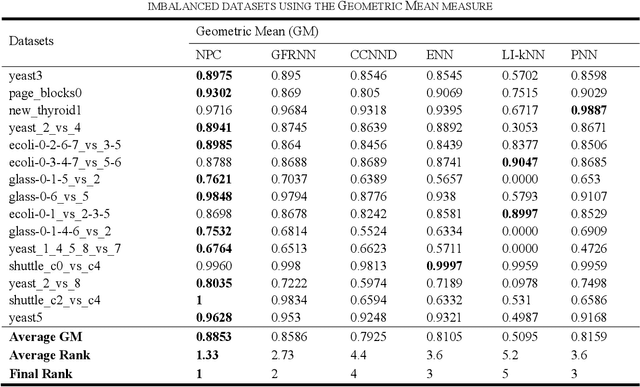

Learning from many real-world datasets is limited by a problem called the class imbalance problem. A dataset is imbalanced when one class (the majority class) has significantly more samples than the other class (the minority class). Such datasets cause typical machine learning algorithms to perform poorly on the classification task. To overcome this issue, this paper proposes a new approach Neighbors Progressive Competition (NPC) for classification of imbalanced datasets. Whilst the proposed algorithm is inspired by weighted k-Nearest Neighbor (k-NN) algorithms, it has major differences from them. Unlike k- NN, NPC does not limit its decision criteria to a preset number of nearest neighbors. In contrast, NPC considers progressively more neighbors of the query sample in its decision making until the sum of grades for one class is much higher than the other classes. Furthermore, NPC uses a novel method for grading the training samples to compensate for the imbalance issue. The grades are calculated using both local and global information. In brief, the contribution of this paper is an entirely new classifier for handling the imbalance issue effectively without any manually-set parameters or any need for expert knowledge. Experimental results compare the proposed approach with five representative algorithms applied to fifteen imbalanced datasets and illustrate this algorithms effectiveness.
Combined A*-Ants Algorithm: A New Multi-Parameter Vehicle Navigation Scheme
Apr 28, 2015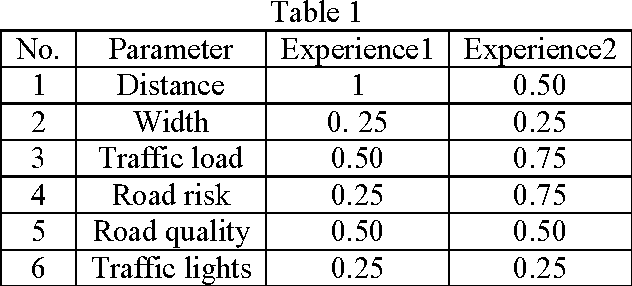

In this paper a multi-parameter A*(A- star)-ants based algorithm is proposed in order to find the best optimized multi-parameter path between two desired points in regions. This algorithm recognizes paths, according to user desired parameters using electronic maps. The proposed algorithm is a combination of A* and ants algorithm in which the proposed A* algorithm is the prologue to the suggested ant based algorithm .In fact, this A* algorithm invigorates some paths pheromones in ants algorithm. As one of implementations of this method, this algorithm was applied on a part of Kerman city, Iran as a multi-parameter vehicle navigator. It finds the best optimized multi-parameter direction between two desired junctions based on city traveler parameters. Comparison results between the proposed method and ants algorithm demonstrates efficiency and lower cost function results of the proposed method versus ants algorithm.