 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality for the global spectrum of random inner-product kernel matrices in the polynomial regime
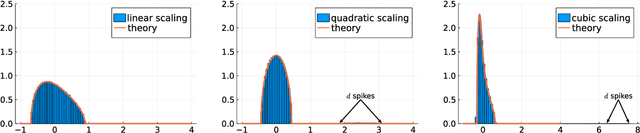
Oct 27, 2023We consider certain large random matrices, called random inner-product kernel matrices, which are essentially given by a nonlinear function $f$ applied entrywise to a sample-covariance matrix, $f(X^TX)$, where $X \in \mathbb{R}^{d \times N}$ is random and normalized in such a way that $f$ typically has order-one arguments. We work in the polynomial regime, where $N \asymp d^\ell$ for some $\ell > 0$, not just the linear regime where $\ell = 1$. Earlier work by various authors showed that, when the columns of $X$ are either uniform on the sphere or standard Gaussian vectors, and when $\ell$ is an integer (the linear regime $\ell = 1$ is particularly well-studied), the bulk eigenvalues of such matrices behave in a simple way: They are asymptotically given by the free convolution of the semicircular and Mar\v{c}enko-Pastur distributions, with relative weights given by expanding $f$ in the Hermite basis. In this paper, we show that this phenomenon is universal, holding as soon as $X$ has i.i.d. entries with all finite moments. In the case of non-integer $\ell$, the Mar\v{c}enko-Pastur term disappears (its weight in the free convolution vanishes), and the spectrum is just semicircular.
An Equivalence Principle for the Spectrum of Random Inner-Product Kernel Matrices
May 12, 2022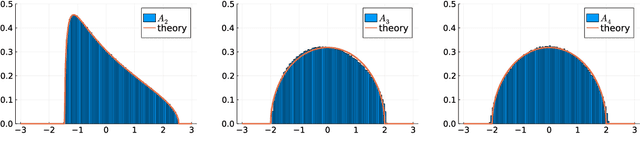
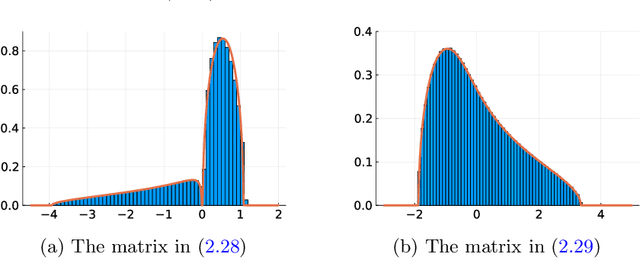
We consider random matrices whose entries are obtained by applying a (nonlinear) kernel function to the pairwise inner products between $n$ independent data vectors drawn uniformly from the unit sphere in $\mathbb{R}^d$. Our study of this model is motivated by problems in machine learning, statistics, and signal processing, where such inner-product kernel random matrices and their spectral properties play important roles. Under mild conditions on the kernel function, we establish the weak-limit of the empirical spectral distribution of these matrices when $d, n \to \infty$ such that $n / d^\ell \to \kappa \in (0, \infty)$, for some fixed $\ell \in \mathbb{N}$ and $\kappa \in \mathbb{R}$. This generalizes an earlier result of Cheng and Singer (2013), who studied the same model in the linear scaling regime (with $\ell = 1$ and $n/d \to \kappa$). The main insight of our work is a general equivalence principle: the spectrum of the random kernel matrix is asymptotically equivalent to that of a simpler matrix model, constructed as the linear combination of a (shifted) Wishart matrix and an independent matrix drawn from the Gaussian orthogonal ensemble. The aspect ratio of the Wishart matrix and the coefficients of the linear combination are determined by $\ell$ and by the expansion of the kernel function in the orthogonal Hermite polynomial basis. Consequently, the limiting spectrum of the random kernel matrix can be characterized as the free additive convolution between a Marchenko-Pastur law and a semicircle law.
Dynamics of Deep Neural Networks and Neural Tangent Hierarchy
Sep 18, 2019The evolution of a deep neural network trained by the gradient descent can be described by its neural tangent kernel (NTK) as introduced in [20], where it was proven that in the infinite width limit the NTK converges to an explicit limiting kernel and it stays constant during training. The NTK was also implicit in some other recent papers [6,13,14]. In the overparametrization regime, a fully-trained deep neural network is indeed equivalent to the kernel regression predictor using the limiting NTK. And the gradient descent achieves zero training loss for a deep overparameterized neural network. However, it was observed in [5] that there is a performance gap between the kernel regression using the limiting NTK and the deep neural networks. This performance gap is likely to originate from the change of the NTK along training due to the finite width effect. The change of the NTK along the training is central to describe the generalization features of deep neural networks. In the current paper, we study the dynamic of the NTK for finite width deep fully-connected neural networks. We derive an infinite hierarchy of ordinary differential equations, the neural tangent hierarchy (NTH) which captures the gradient descent dynamic of the deep neural network. Moreover, under certain conditions on the neural network width and the data set dimension, we prove that the truncated hierarchy of NTH approximates the dynamic of the NTK up to arbitrary precision. This description makes it possible to directly study the change of the NTK for deep neural networks, and sheds light on the observation that deep neural networks outperform kernel regressions using the corresponding limiting NTK.