 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiwu-PyTorch-Plugin: Bridging Deep Learning and Photonic Quantum Computing for Energy-Based Models and Active Sample Selection
Feb 22, 2026This paper introduces the Kaiwu-PyTorch-Plugin (KPP) to bridge Deep Learning and Photonic Quantum Computing across multiple dimensions. KPP integrates the Coherent Ising Machine into the PyTorch ecosystem, addressing classical inefficiencies in Energy-Based Models. The framework facilitates quantum integration in three key aspects: accelerating Boltzmann sampling, optimizing training data via Active Sampling, and constructing hybrid architectures like QBM-VAE and Q-Diffusion. Empirical results on single-cell and OpenWebText datasets demonstrate KPPs ability to achieve SOTA performance, validating a comprehensive quantum-classical paradigm.
Automated Timeline Length Selection for Flexible Timeline Summarization
May 29, 2021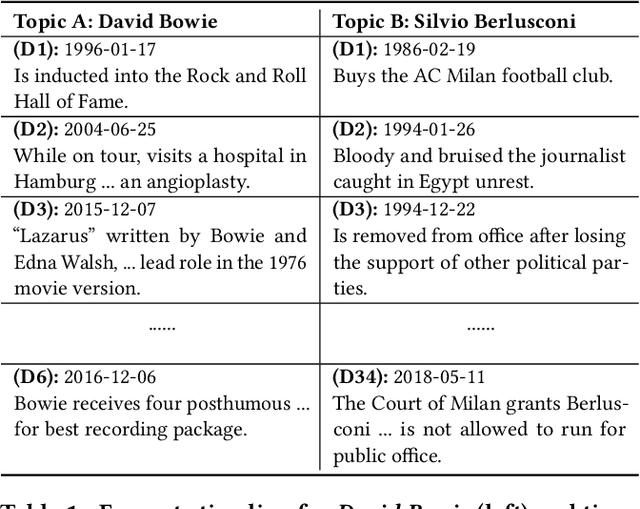
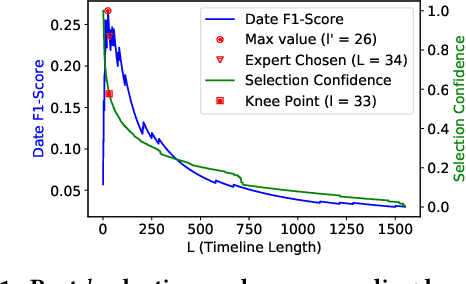
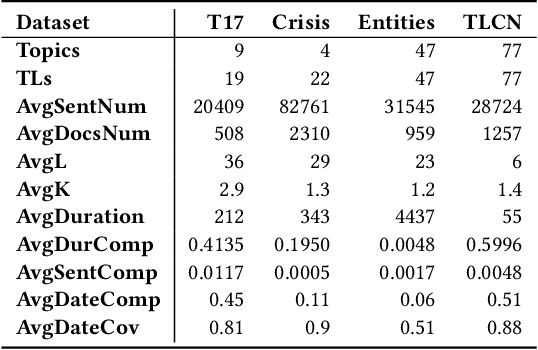
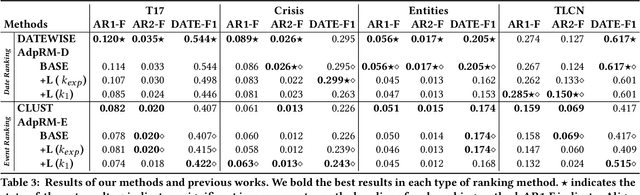
By producing summaries for long-running events, timeline summarization (TLS) underpins many information retrieval tasks. Successful TLS requires identifying an appropriate set of key dates (the timeline length) to cover. However, doing so is challenging as the right length can change from one topic to another. Existing TLS solutions either rely on an event-agnostic fixed length or an expert-supplied setting. Neither of the strategies is desired for real-life TLS scenarios. A fixed, event-agnostic setting ignores the diversity of events and their development and hence can lead to low-quality TLS. Relying on expert-crafted settings is neither scalable nor sustainable for processing many dynamically changing events. This paper presents a better TLS approach for automatically and dynamically determining the TLS timeline length. We achieve this by employing the established elbow method from the machine learning community to automatically find the minimum number of dates within the time series to generate concise and informative summaries. We applied our approach to four TLS datasets of English and Chinese and compared them against three prior methods. Experimental results show that our approach delivers comparable or even better summaries over state-of-art TLS methods, but it achieves this without expert involvement.
Noised Consistency Training for Text Summarization
May 28, 2021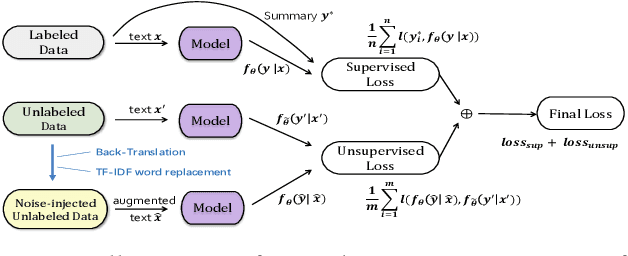
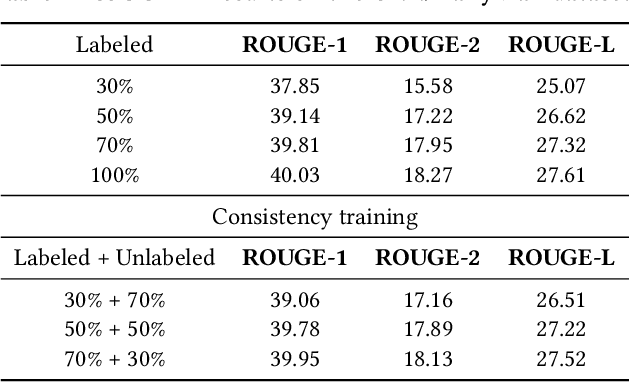
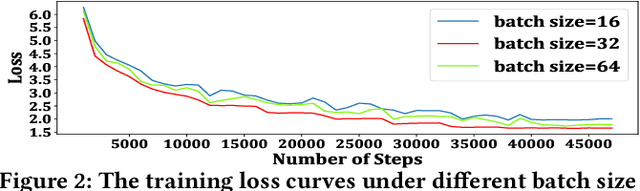
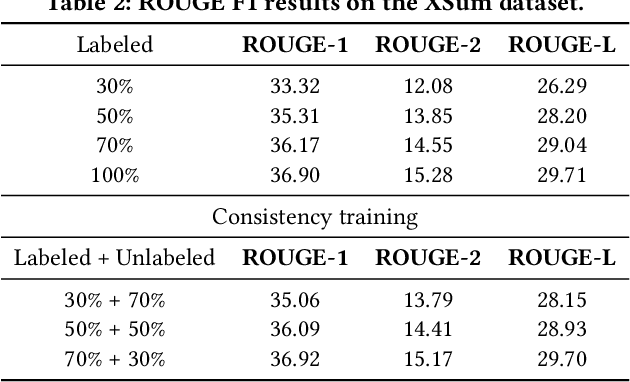
Neural abstractive summarization methods often require large quantities of labeled training data. However, labeling large amounts of summarization data is often prohibitive due to time, financial, and expertise constraints, which has limited the usefulness of summarization systems to practical applications. In this paper, we argue that this limitation can be overcome by a semi-supervised approach: consistency training which is to leverage large amounts of unlabeled data to improve the performance of supervised learning over a small corpus. The consistency regularization semi-supervised learning can regularize model predictions to be invariant to small noise applied to input articles. By adding noised unlabeled corpus to help regularize consistency training, this framework obtains comparative performance without using the full dataset. In particular, we have verified that leveraging large amounts of unlabeled data decently improves the performance of supervised learning over an insufficient labeled dataset.