 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Arms Bandit: Optimality via Confidence Bounds
May 30, 2018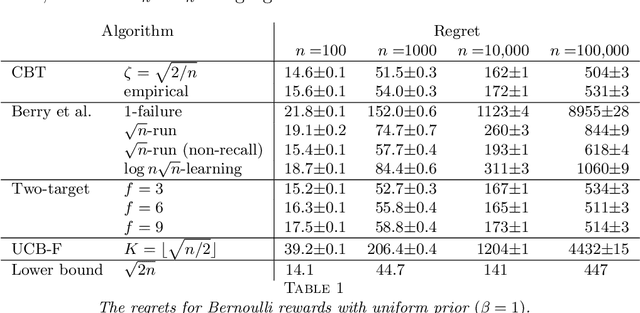
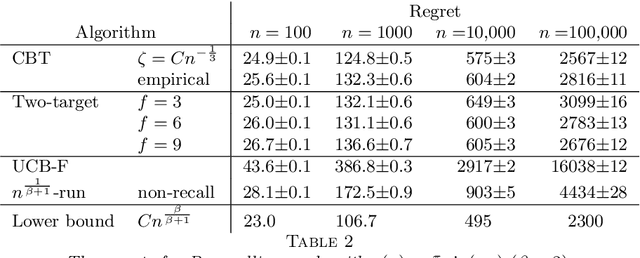
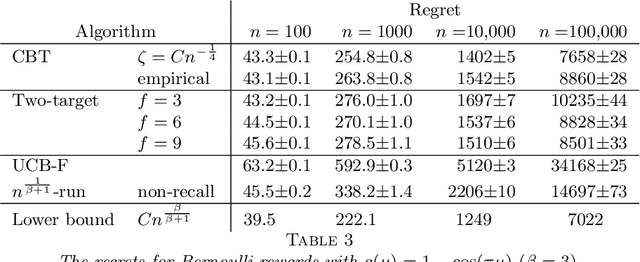
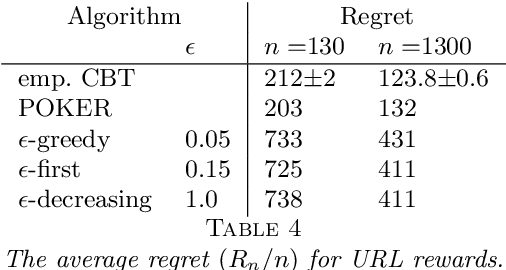
The infinite arms bandit problem was initiated by Berry et al. (1997). They derived a regret lower bound of all solutions for Bernoulli rewards, and proposed various bandit strategies based on success runs, but which do not achieve this bound. We propose here a confidence bound target (CBT) algorithm that achieves extensions of their regret lower bound for general reward distributions and distribution priors. The algorithm does not require information on the reward distributions, for each arm we require only the mean and standard deviation of its rewards to compute a confidence bound. We play the arm with the smallest confidence bound provided it is smaller than a target mean. If the confidence bounds are all larger, then we play a new arm. We show how the target mean can be computed from the prior so that the smallest asymptotic regret, among all infinite arms bandit algorithms, is achieved. We also show that in the absence of information on the prior, the target mean can be determined empirically, and that the regret achieved is comparable to the smallest regret. Numerical studies show that CBT is versatile and outperforms its competitors.