Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeur-iw-hnt at GermEval 2021: An Ensembling Strategy with Multiple BERT Models
Oct 05, 2021

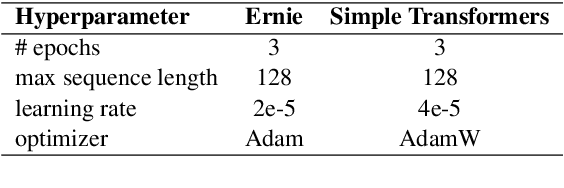

This paper describes our approach (ur-iw-hnt) for the Shared Task of GermEval2021 to identify toxic, engaging, and fact-claiming comments. We submitted three runs using an ensembling strategy by majority (hard) voting with multiple different BERT models of three different types: German-based, Twitter-based, and multilingual models. All ensemble models outperform single models, while BERTweet is the winner of all individual models in every subtask. Twitter-based models perform better than GermanBERT models, and multilingual models perform worse but by a small margin.
* In Proceedings of the GermEval 2021 Workshop on the Identification
of Toxic, Engaging, and Fact-Claiming Comments: 17th Conference on Natural
Language Processing KONVENS 2021, pages 83-87, Online (2021)
* 5 pages, 1 figure
* 5 pages, 1 figure
Via