 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiGIT: Multi-Dilated Gated Encoder and Central-Adjacent Region Integrated Decoder for Temporal Action Detection Transformer
May 09, 2025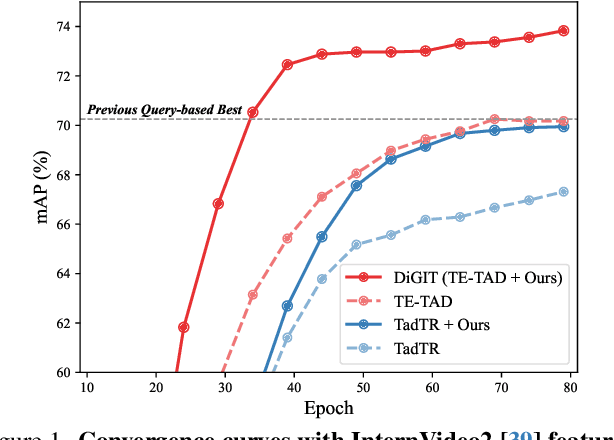

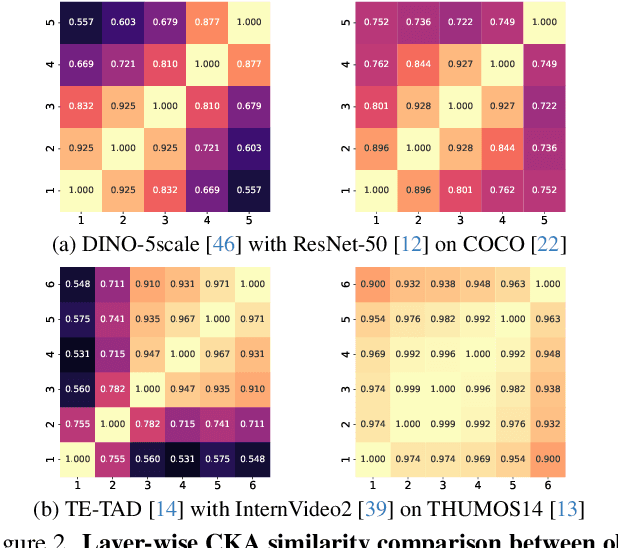

In this paper, we examine a key limitation in query-based detectors for temporal action detection (TAD), which arises from their direct adaptation of originally designed architectures for object detection. Despite the effectiveness of the existing models, they struggle to fully address the unique challenges of TAD, such as the redundancy in multi-scale features and the limited ability to capture sufficient temporal context. To address these issues, we propose a multi-dilated gated encoder and central-adjacent region integrated decoder for temporal action detection transformer (DiGIT). Our approach replaces the existing encoder that consists of multi-scale deformable attention and feedforward network with our multi-dilated gated encoder. Our proposed encoder reduces the redundant information caused by multi-level features while maintaining the ability to capture fine-grained and long-range temporal information. Furthermore, we introduce a central-adjacent region integrated decoder that leverages a more comprehensive sampling strategy for deformable cross-attention to capture the essential information. Extensive experiments demonstrate that DiGIT achieves state-of-the-art performance on THUMOS14, ActivityNet v1.3, and HACS-Segment. Code is available at: https://github.com/Dotori-HJ/DiGIT
Enhancing Multimodal Query Representation via Visual Dialogues for End-to-End Knowledge Retrieval
Nov 13, 2024Existing multimodal retrieval systems often rely on disjointed models for image comprehension, such as object detectors and caption generators, leading to cumbersome implementations and training processes. To overcome this limitation, we propose an end-to-end retrieval system, Ret-XKnow, to endow a text retriever with the ability to understand multimodal queries via dynamic modality interaction. Ret-XKnow leverages a partial convolution mechanism to focus on visual information relevant to the given textual query, thereby enhancing multimodal query representations. To effectively learn multimodal interaction, we also introduce the Visual Dialogue-to-Retrieval (ViD2R) dataset automatically constructed from visual dialogue datasets. Our dataset construction process ensures that the dialogues are transformed into suitable information retrieval tasks using a text retriever. We demonstrate that our approach not only significantly improves retrieval performance in zero-shot settings but also achieves substantial improvements in fine-tuning scenarios. Our code is publicly available: https://github.com/yeongjoonJu/Ret_XKnow.
TE-TAD: Towards Full End-to-End Temporal Action Detection via Time-Aligned Coordinate Expression
Apr 04, 2024In this paper, we investigate that the normalized coordinate expression is a key factor as reliance on hand-crafted components in query-based detectors for temporal action detection (TAD). Despite significant advancements towards an end-to-end framework in object detection, query-based detectors have been limited in achieving full end-to-end modeling in TAD. To address this issue, we propose \modelname{}, a full end-to-end temporal action detection transformer that integrates time-aligned coordinate expression. We reformulate coordinate expression utilizing actual timeline values, ensuring length-invariant representations from the extremely diverse video duration environment. Furthermore, our proposed adaptive query selection dynamically adjusts the number of queries based on video length, providing a suitable solution for varying video durations compared to a fixed query set. Our approach not only simplifies the TAD process by eliminating the need for hand-crafted components but also significantly improves the performance of query-based detectors. Our TE-TAD outperforms the previous query-based detectors and achieves competitive performance compared to state-of-the-art methods on popular benchmark datasets. Code is available at: https://github.com/Dotori-HJ/TE-TAD