 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord2Vec is a special case of Kernel Correspondence Analysis and Kernels for Natural Language Processing
Aug 14, 2016



We show Correspondence Analysis (CA) is equivalent to defining Gini-index with appropriate scaled one-hot encoding. Using this relation, we introduce non-linear kernel extension of CA. The extended CA gives well-known analysis for categorical data (CD) and natural language processing by specializing kernels. For example, our formulation can give G-test, skip-gram with negative-sampling (SGNS), and GloVe as a special case. We introduce two kernels for natural language processing based on our formulation. First is a stop word(SW) kernel. Second is word similarity(WS) kernel. The SW kernel is the system introducing appropriate weights for SW. The WS kernel enables to use WS test data as training data for vector space representations of words. We show these kernels enhances accuracy when training data is not sufficiently large.
Image processing using miniKanren
Mar 16, 2014
An integral image is one of the most efficient optimization technique for image processing. However an integral image is only a special case of delayed stream or memoization. This research discusses generalizing concept of integral image optimization technique, and how to generate an integral image optimized program code automatically from abstracted image processing algorithm. In oder to abstruct algorithms, we forces to miniKanren.
Covariance and PCA for Categorical Variables
Nov 28, 2007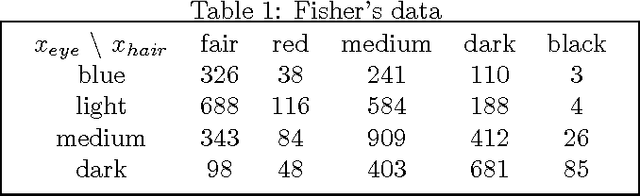



Covariances from categorical variables are defined using a regular simplex expression for categories. The method follows the variance definition by Gini, and it gives the covariance as a solution of simultaneous equations. The calculated results give reasonable values for test data. A method of principal component analysis (RS-PCA) is also proposed using regular simplex expressions, which allows easy interpretation of the principal components. The proposed methods apply to variable selection problem of categorical data USCensus1990 data. The proposed methods give appropriate criterion for the variable selection problem of categorical