 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Friendly Delayed-Feedback Reservoir for Multivariate Time-Series Classification
Apr 16, 2025Reservoir computing (RC) is attracting attention as a machine-learning technique for edge computing. In time-series classification tasks, the number of features obtained using a reservoir depends on the length of the input series. Therefore, the features must be converted to a constant-length intermediate representation (IR), such that they can be processed by an output layer. Existing conversion methods involve computationally expensive matrix inversion that significantly increases the circuit size and requires processing power when implemented in hardware. In this article, we propose a simple but effective IR, namely, dot-product-based reservoir representation (DPRR), for RC based on the dot product of data features. Additionally, we propose a hardware-friendly delayed-feedback reservoir (DFR) consisting of a nonlinear element and delayed feedback loop with DPRR. The proposed DFR successfully classified multivariate time series data that has been considered particularly difficult to implement efficiently in hardware. In contrast to conventional DFR models that require analog circuits, the proposed model can be implemented in a fully digital manner suitable for high-level syntheses. A comparison with existing machine-learning methods via field-programmable gate array implementation using 12 multivariate time-series classification tasks confirmed the superior accuracy and small circuit size of the proposed method.
Window Function-less DFT with Reduced Noise and Latency for Real-Time Music Analysis
Oct 10, 2024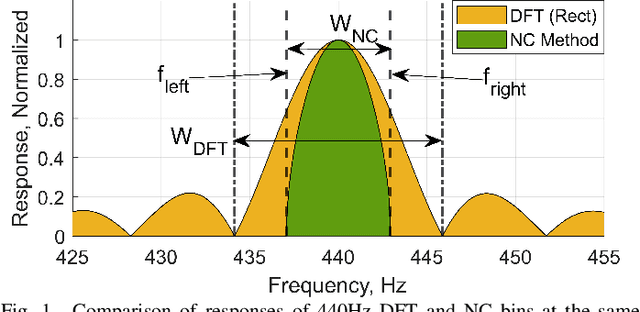
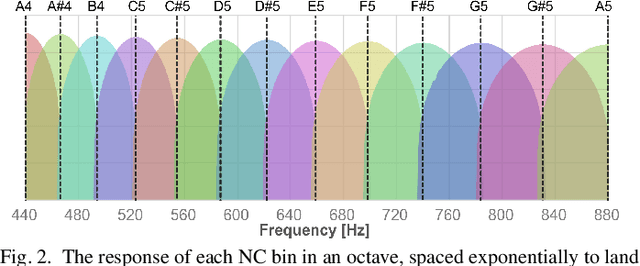
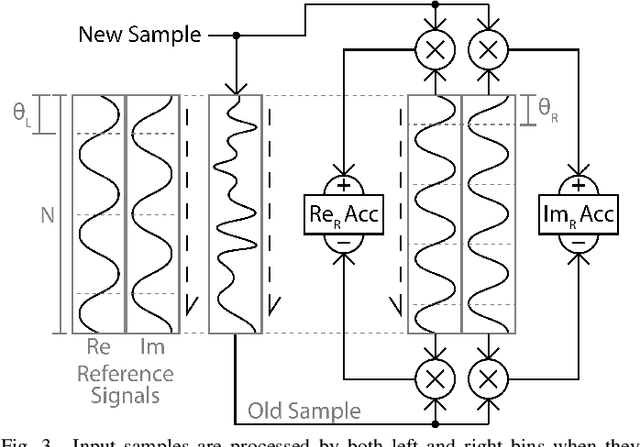
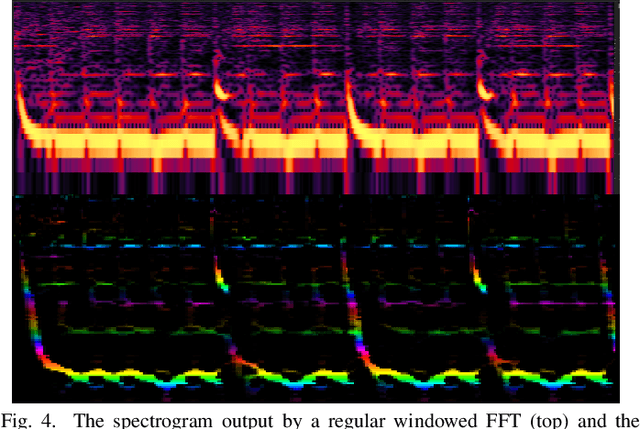
Music analysis applications demand algorithms that can provide both high time and frequency resolution while minimizing noise in an already-noisy signal. Real-time analysis additionally demands low latency and low computational requirements. We propose a DFT-based algorithm that accomplishes all these requirements by extending a method that post-processes DFT output without the use of window functions. Our approach yields greatly reduced sidelobes and noise, and improves time resolution without sacrificing frequency resolution. We use exponentially spaced output bins which directly map to notes in music. The resulting improved performance, compared to existing FFT and DFT-based approaches, creates possibilities for improved real-time visualizations, and contributes to improved analysis quality in other applications such as automatic transcription.
Modular DFR: Digital Delayed Feedback Reservoir Model for Enhancing Design Flexibility
Jul 05, 2023A delayed feedback reservoir (DFR) is a type of reservoir computing system well-suited for hardware implementations owing to its simple structure. Most existing DFR implementations use analog circuits that require both digital-to-analog and analog-to-digital converters for interfacing. However, digital DFRs emulate analog nonlinear components in the digital domain, resulting in a lack of design flexibility and higher power consumption. In this paper, we propose a novel modular DFR model that is suitable for fully digital implementations. The proposed model reduces the number of hyperparameters and allows flexibility in the selection of the nonlinear function, which improves the accuracy while reducing the power consumption. We further present two DFR realizations with different nonlinear functions, achieving 10x power reduction and 5.3x throughput improvement while maintaining equal or better accuracy.
Binary Neural Network in Robotic Manipulation: Flexible Object Manipulation for Humanoid Robot Using Partially Binarized Auto-Encoder on FPGA
Jul 01, 2021



A neural network based flexible object manipulation system for a humanoid robot on FPGA is proposed. Although the manipulations of flexible objects using robots attract ever increasing attention since these tasks are the basic and essential activities in our daily life, it has been put into practice only recently with the help of deep neural networks. However such systems have relied on GPU accelerators, which cannot be implemented into the space limited robotic body. Although field programmable gate arrays (FPGAs) are known to be energy efficient and suitable for embedded systems, the model size should be drastically reduced since FPGAs have limited on-chip memory. To this end, we propose ``partially'' binarized deep convolutional auto-encoder technique, where only an encoder part is binarized to compress model size without degrading the inference accuracy. The model implemented on Xilinx ZCU102 achieves 41.1 frames per second with a power consumption of 3.1W, {\awano{which corresponds to 10x and 3.7x improvements from the systems implemented on Core i7 6700K and RTX 2080 Ti, respectively.