 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyControlEdge: A Foundation-Model Fine-Tuning for Edge Detection
Feb 18, 2026We propose EasyControlEdge, adapting an image-generation foundation model to edge detection. In real-world edge detection (e.g., floor-plan walls, satellite roads/buildings, and medical organ boundaries), crispness and data efficiency are crucial, yet producing crisp raw edge maps with limited training samples remains challenging. Although image-generation foundation models perform well on many downstream tasks, their pretrained priors for data-efficient transfer and iterative refinement for high-frequency detail preservation remain underexploited for edge detection. To enable crisp and data-efficient edge detection using these capabilities, we introduce an edge-specialized adaptation of image-generation foundation models. To better specialize the foundation model for edge detection, we incorporate an edge-oriented objective with an efficient pixel-space loss. At inference, we introduce guidance based on unconditional dynamics, enabling a single model to control the edge density through a guidance scale. Experiments on BSDS500, NYUDv2, BIPED, and CubiCasa compare against state-of-the-art methods and show consistent gains, particularly under no-post-processing crispness evaluation and with limited training data.
Representation Synthesis by Probabilistic Many-Valued Logic Operation in Self-Supervised Learning
Sep 08, 2023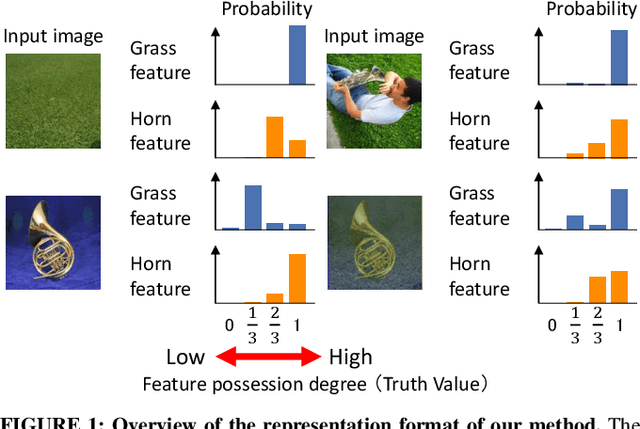



Self-supervised learning (SSL) using mixed images has been studied to learn various image representations. Existing methods using mixed images learn a representation by maximizing the similarity between the representation of the mixed image and the synthesized representation of the original images. However, few methods consider the synthesis of representations from the perspective of mathematical logic. In this study, we focused on a synthesis method of representations. We proposed a new SSL with mixed images and a new representation format based on many-valued logic. This format can indicate the feature-possession degree, that is, how much of each image feature is possessed by a representation. This representation format and representation synthesis by logic operation realize that the synthesized representation preserves the remarkable characteristics of the original representations. Our method performed competitively with previous representation synthesis methods for image classification tasks. We also examined the relationship between the feature-possession degree and the number of classes of images in the multilabel image classification dataset to verify that the intended learning was achieved. In addition, we discussed image retrieval, which is an application of our proposed representation format using many-valued logic.
Self-Supervised Representation Learning as Multimodal Variational Inference
Mar 22, 2022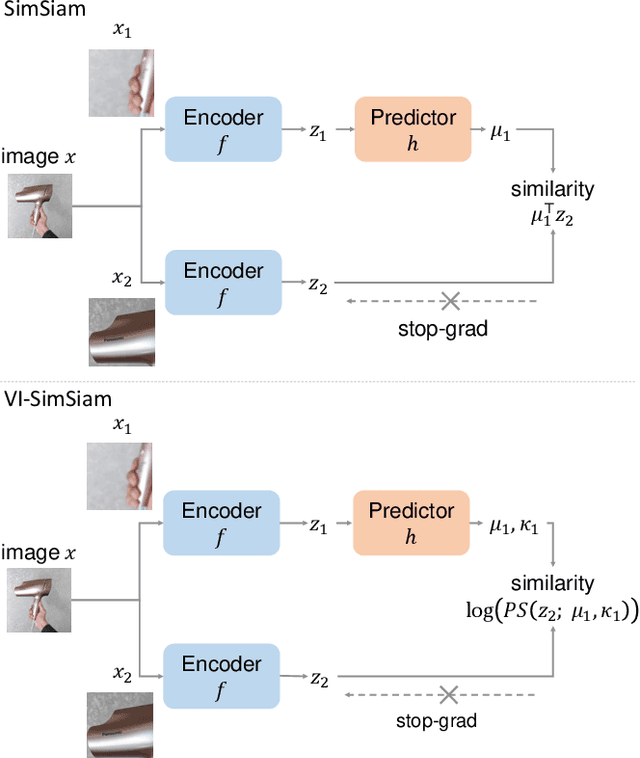

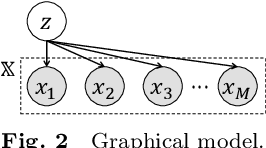
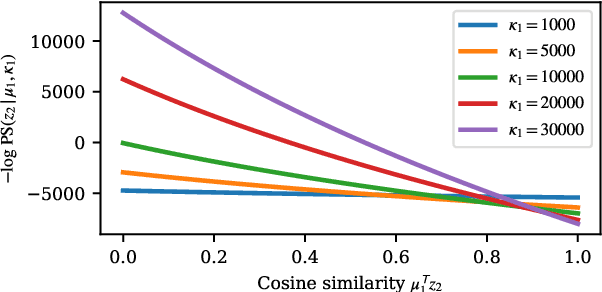
This paper proposes a probabilistic extension of SimSiam, a recent self-supervised learning (SSL) method. SimSiam trains a model by maximizing the similarity between image representations of different augmented views of the same image. Although uncertainty-aware machine learning has been getting general like deep variational inference, SimSiam and other SSL are insufficiently uncertainty-aware, which could lead to limitations on its potential. The proposed extension is to make SimSiam uncertainty-aware based on variational inference. Our main contributions are twofold: Firstly, we clarify the theoretical relationship between non-contrastive SSL and multimodal variational inference. Secondly, we introduce a novel SSL called variational inference SimSiam (VI-SimSiam), which incorporates the uncertainty by involving spherical posterior distributions. Our experiment shows that VI-SimSiam outperforms SimSiam in classification tasks in ImageNette and ImageWoof by successfully estimating the representation uncertainty.