 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap to Domain Knowledge Integration in Machine Learning
Dec 12, 2022Many machine learning algorithms have been developed in recent years to enhance the performance of a model in different aspects of artificial intelligence. But the problem persists due to inadequate data and resources. Integrating knowledge in a machine learning model can help to overcome these obstacles up to a certain degree. Incorporating knowledge is a complex task though because of various forms of knowledge representation. In this paper, we will give a brief overview of these different forms of knowledge integration and their performance in certain machine learning tasks.
Knowledge Distillation via Weighted Ensemble of Teaching Assistants
Jun 23, 2022
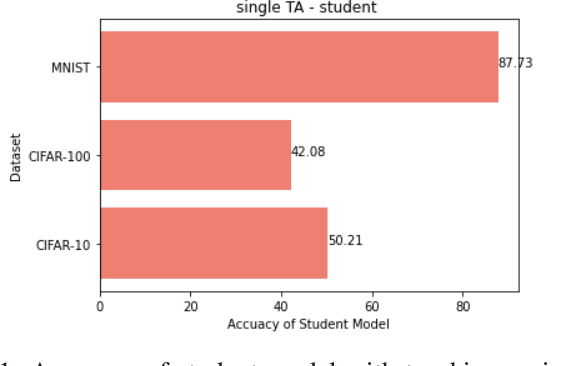


Knowledge distillation in machine learning is the process of transferring knowledge from a large model called the teacher to a smaller model called the student. Knowledge distillation is one of the techniques to compress the large network (teacher) to a smaller network (student) that can be deployed in small devices such as mobile phones. When the network size gap between the teacher and student increases, the performance of the student network decreases. To solve this problem, an intermediate model is employed between the teacher model and the student model known as the teaching assistant model, which in turn bridges the gap between the teacher and the student. In this research, we have shown that using multiple teaching assistant models, the student model (the smaller model) can be further improved. We combined these multiple teaching assistant models using weighted ensemble learning where we have used a differential evaluation optimization algorithm to generate the weight values.