 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALF: A Conditionally Adaptive Loss Function to Mitigate Class-Imbalanced Segmentation
Apr 06, 2025



Imbalanced datasets pose a considerable challenge in training deep learning (DL) models for medical diagnostics, particularly for segmentation tasks. Imbalance may be associated with annotation quality limited annotated datasets, rare cases, or small-scale regions of interest (ROIs). These conditions adversely affect model training and performance, leading to segmentation boundaries which deviate from the true ROIs. Traditional loss functions, such as Binary Cross Entropy, replicate annotation biases and limit model generalization. We propose a novel, statistically driven, conditionally adaptive loss function (CALF) tailored to accommodate the conditions of imbalanced datasets in DL training. It employs a data-driven methodology by estimating imbalance severity using statistical methods of skewness and kurtosis, then applies an appropriate transformation to balance the training dataset while preserving data heterogeneity. This transformative approach integrates a multifaceted process, encompassing preprocessing, dataset filtering, and dynamic loss selection to achieve optimal outcomes. We benchmark our method against conventional loss functions using qualitative and quantitative evaluations. Experiments using large-scale open-source datasets (i.e., UPENN-GBM, UCSF, LGG, and BraTS) validate our approach, demonstrating substantial segmentation improvements. Code availability: https://anonymous.4open.science/r/MICCAI-Submission-43F9/.
Online GANs for Automatic Performance Testing
Apr 21, 2021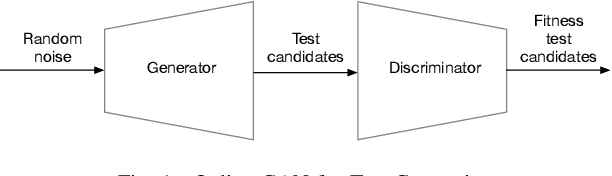
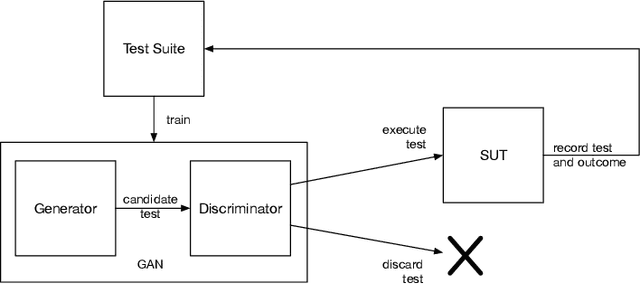
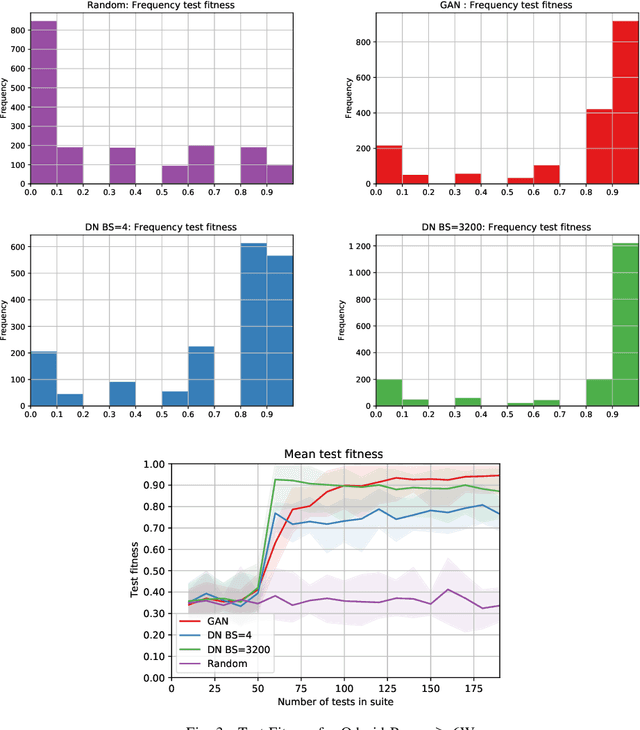

In this paper we present a novel algorithm for automatic performance testing that uses an online variant of the Generative Adversarial Network (GAN) to optimize the test generation process. The objective of the proposed approach is to generate, for a given test budget, a test suite containing a high number of tests revealing performance defects. This is achieved using a GAN to generate the tests and predict their outcome. This GAN is trained online while generating and executing the tests. The proposed approach does not require a prior training set or model of the system under test. We provide an initial evaluation the algorithm using an example test system, and compare the obtained results with other possible approaches. We consider that the presented algorithm serves as a proof of concept and we hope that it can spark a research discussion on the application of GANs to test generation.
Data Collection and Acceleration Infrastructure for FPGA-based Edge AI Applications
Mar 11, 2021
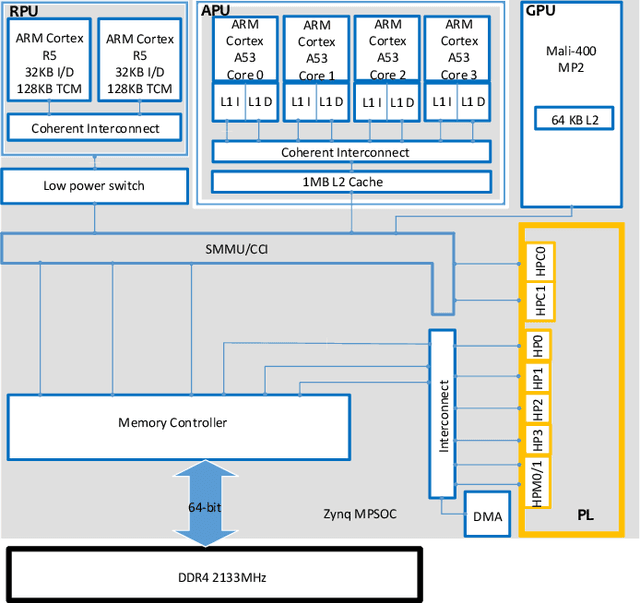
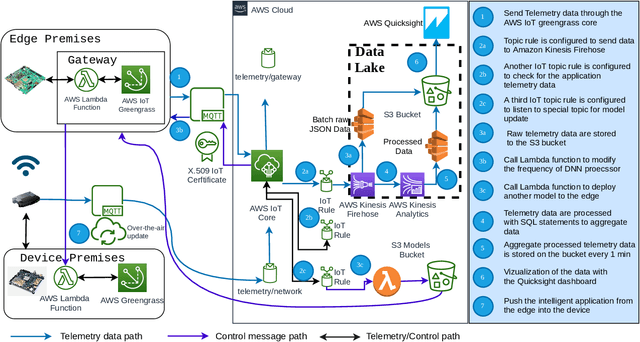
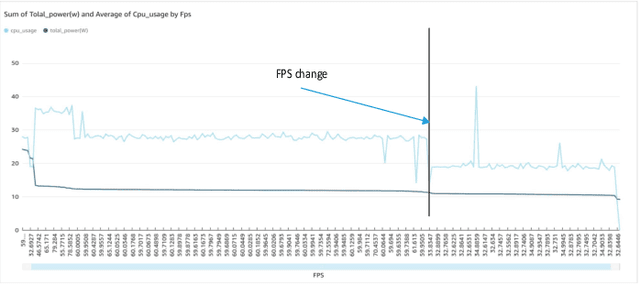
As data being produced by IoT applications continues to explode, there's a growing need to bring computing power closer to the source of the data to meet the response-time, power-consumption and cost goals of performance-critical applications like Industrial Internet of Things (IIoT), Automated Driving, Medical Imaging or Surveillance among others. This paper proposes a FPGA-based data collection and utilization framework that allows runtime platform and application data to be sent to an edge and cloud system via data collection agents running close to the platform. Agents are connected to a cloud system able to train AI models to improve overall energy efficiency of an AI application executed on a FPGA-based edge platform. In the implementation part we show that it is feasible to collect relevant data from an FPGA platform, transmit the data to a cloud system for processing and receiving feedback actions to execute an edge AI application energy efficiently. As future work we foresee the possibility to train, deploy and continuously improve a base model able to efficiently adapt the execution of edge applications.