 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm-Agnostic Interpretations for Clustering
Sep 21, 2022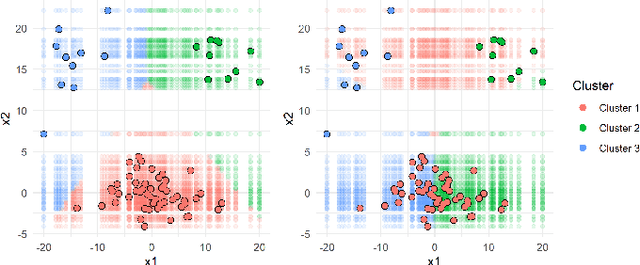
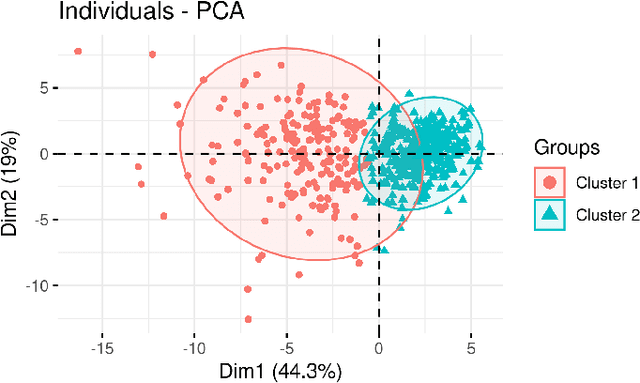
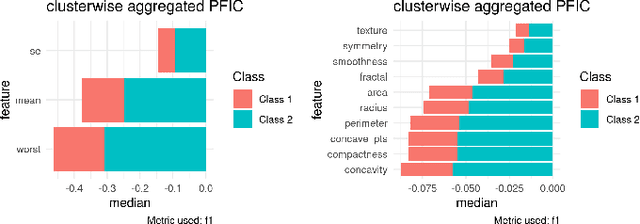
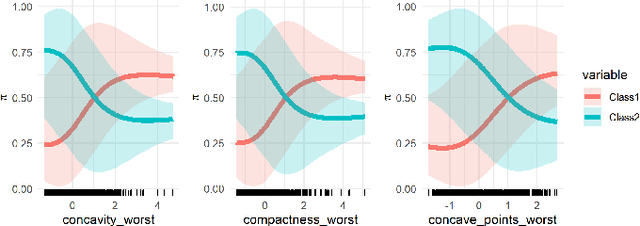
A clustering outcome for high-dimensional data is typically interpreted via post-processing, involving dimension reduction and subsequent visualization. This destroys the meaning of the data and obfuscates interpretations. We propose algorithm-agnostic interpretation methods to explain clustering outcomes in reduced dimensions while preserving the integrity of the data. The permutation feature importance for clustering represents a general framework based on shuffling feature values and measuring changes in cluster assignments through custom score functions. The individual conditional expectation for clustering indicates observation-wise changes in the cluster assignment due to changes in the data. The partial dependence for clustering evaluates average changes in cluster assignments for the entire feature space. All methods can be used with any clustering algorithm able to reassign instances through soft or hard labels. In contrast to common post-processing methods such as principal component analysis, the introduced methods maintain the original structure of the features.