 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJam-ALT: A Formatting-Aware Lyrics Transcription Benchmark
Nov 23, 2023



Current automatic lyrics transcription (ALT) benchmarks focus exclusively on word content and ignore the finer nuances of written lyrics including formatting and punctuation, which leads to a potential misalignment with the creative products of musicians and songwriters as well as listeners' experiences. For example, line breaks are important in conveying information about rhythm, emotional emphasis, rhyme, and high-level structure. To address this issue, we introduce Jam-ALT, a new lyrics transcription benchmark based on the JamendoLyrics dataset. Our contribution is twofold. Firstly, a complete revision of the transcripts, geared specifically towards ALT evaluation by following a newly created annotation guide that unifies the music industry's guidelines, covering aspects such as punctuation, line breaks, spelling, background vocals, and non-word sounds. Secondly, a suite of evaluation metrics designed, unlike the traditional word error rate, to capture such phenomena. We hope that the proposed benchmark contributes to the ALT task, enabling more precise and reliable assessments of transcription systems and enhancing the user experience in lyrics applications such as subtitle renderings for live captioning or karaoke.
Musical Tempo and Key Estimation using Convolutional Neural Networks with Directional Filters
Mar 26, 2019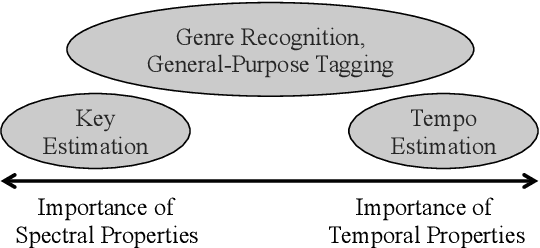
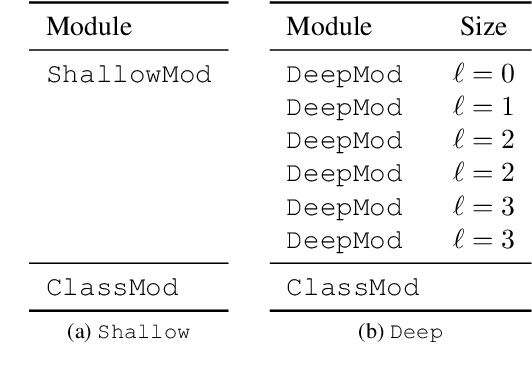
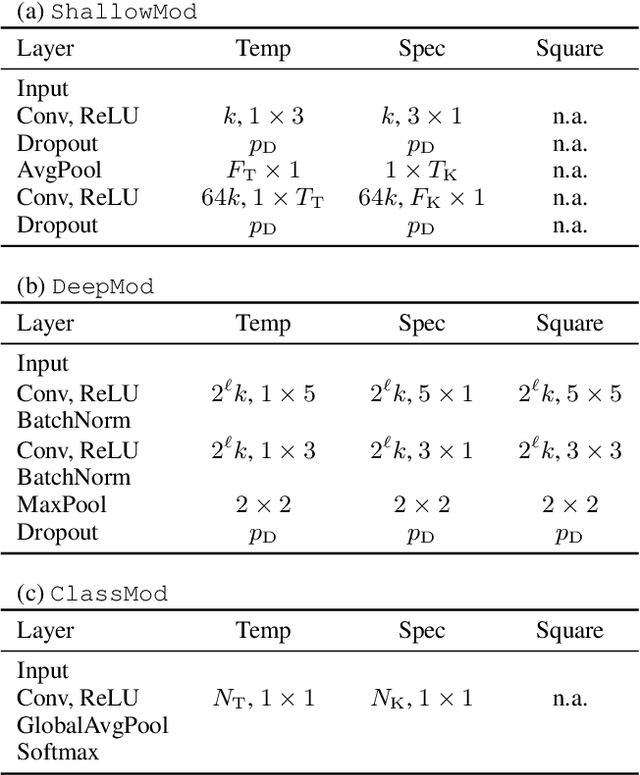
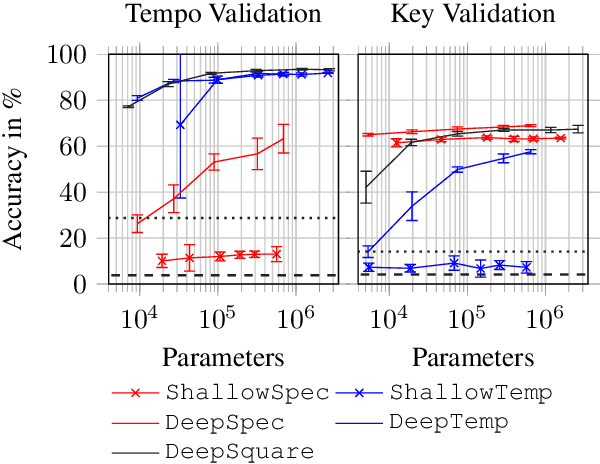
In this article we explore how the different semantics of spectrograms' time and frequency axes can be exploited for musical tempo and key estimation using Convolutional Neural Networks (CNN). By addressing both tasks with the same network architectures ranging from shallow, domain-specific approaches to deep variants with directional filters, we show that axis-aligned architectures perform similarly well as common VGG-style networks developed for computer vision, while being less vulnerable to confounding factors and requiring fewer model parameters.