 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstLLM: Enhancing Estonian Capabilities in Multilingual LLMs via Continued Pretraining and Post-Training
Mar 02, 2026Large language models (LLMs) are predominantly trained on English-centric data, resulting in uneven performance for smaller languages. We study whether continued pretraining (CPT) can substantially improve Estonian capabilities in a pretrained multilingual LLM while preserving its English and general reasoning performance. Using Llama 3.1 8B as the main base model, we perform CPT on a mixture that increases Estonian exposure while approximating the original training distribution through English replay and the inclusion of code, mathematics, and instruction-like data. We subsequently apply supervised fine-tuning, preference optimization, and chat vector merging to introduce robust instruction-following behavior. Evaluation on a comprehensive suite of Estonian benchmarks shows consistent gains in linguistic competence, knowledge, reasoning, translation quality, and instruction-following compared to the original base model and its instruction-tuned variant, while maintaining competitive performance on English benchmarks. These findings indicate that CPT, with an appropriately balanced data mixture, together with post-training alignment, can substantially improve single-language capabilities in pretrained multilingual LLMs.
LLMs for Extremely Low-Resource Finno-Ugric Languages
Oct 24, 2024
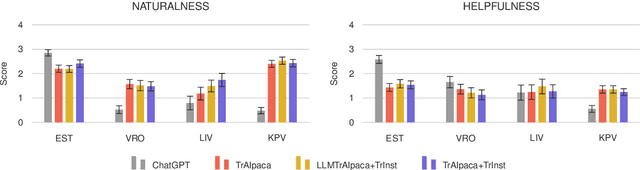
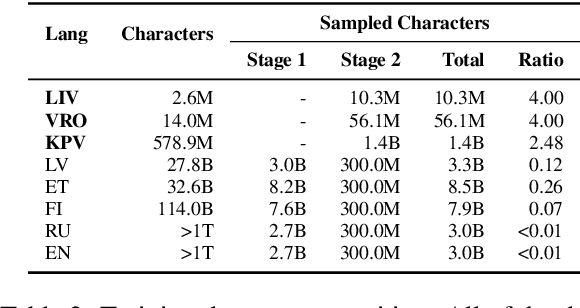
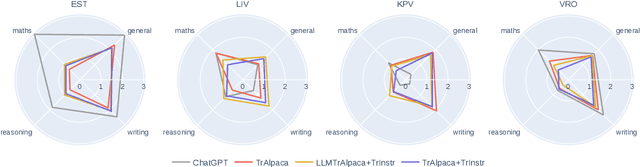
The advancement of large language models (LLMs) has predominantly focused on high-resource languages, leaving low-resource languages, such as those in the Finno-Ugric family, significantly underrepresented. This paper addresses this gap by focusing on V\~oro, Livonian, and Komi. We cover almost the entire cycle of LLM creation, from data collection to instruction tuning and evaluation. Our contributions include developing multilingual base and instruction-tuned models; creating evaluation benchmarks, including the smugri-MT-bench multi-turn conversational benchmark; and conducting human evaluation. We intend for this work to promote linguistic diversity, ensuring that lesser-resourced languages can benefit from advancements in NLP.
Teaching Llama a New Language Through Cross-Lingual Knowledge Transfer
Apr 05, 2024This paper explores cost-efficient methods to adapt pretrained Large Language Models (LLMs) to new lower-resource languages, with a specific focus on Estonian. Leveraging the Llama 2 model, we investigate the impact of combining cross-lingual instruction-tuning with additional monolingual pretraining. Our results demonstrate that even a relatively small amount of additional monolingual pretraining followed by cross-lingual instruction-tuning significantly enhances results on Estonian. Furthermore, we showcase cross-lingual knowledge transfer from high-quality English instructions to Estonian, resulting in improvements in commonsense reasoning and multi-turn conversation capabilities. Our best model, named \textsc{Llammas}, represents the first open-source instruction-following LLM for Estonian. Additionally, we publish Alpaca-est, the first general task instruction dataset for Estonia. These contributions mark the initial progress in the direction of developing open-source LLMs for Estonian.
Kratt: Developing an Automatic Subject Indexing Tool for The National Library of Estonia
Mar 24, 2022Manual subject indexing in libraries is a time-consuming and costly process and the quality of the assigned subjects is affected by the cataloguer's knowledge on the specific topics contained in the book. Trying to solve these issues, we exploited the opportunities arising from artificial intelligence to develop Kratt: a prototype of an automatic subject indexing tool. Kratt is able to subject index a book independent of its extent and genre with a set of keywords present in the Estonian Subject Thesaurus. It takes Kratt approximately 1 minute to subject index a book, outperforming humans 10-15 times. Although the resulting keywords were not considered satisfactory by the cataloguers, the ratings of a small sample of regular library users showed more promise. We also argue that the results can be enhanced by including a bigger corpus for training the model and applying more careful preprocessing techniques.
* This is a preprint version. It has 12 pages, 5 figures, 3 tables