 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiQSS: Post-Transformer Linear Quantum-Inspired State-Space Tensor Networks for Real-Time 6G
Jan 18, 2026Proactive and agentic control in Sixth-Generation (6G) Open Radio Access Networks (O-RAN) requires control-grade prediction under stringent Near-Real-Time (Near-RT) latency and computational constraints. While Transformer-based models are effective for sequence modeling, their quadratic complexity limits scalability in Near-RT RAN Intelligent Controller (RIC) analytics. This paper investigates a post-Transformer design paradigm for efficient radio telemetry forecasting. We propose a quantum-inspired many-body state-space tensor network that replaces self-attention with stable structured state-space dynamics kernels, enabling linear-time sequence modeling. Tensor-network factorizations in the form of Tensor Train (TT) / Matrix Product State (MPS) representations are employed to reduce parameterization and data movement in both input projections and prediction heads, while lightweight channel gating and mixing layers capture non-stationary cross-Key Performance Indicator (KPI) dependencies. The proposed model is instantiated as an agentic perceive-predict xApp and evaluated on a bespoke O-RAN KPI time-series dataset comprising 59,441 sliding windows across 13 KPIs, using Reference Signal Received Power (RSRP) forecasting as a representative use case. Our proposed Linear Quantum-Inspired State-Space (LiQSS) model is 10.8x-15.8x smaller and approximately 1.4x faster than prior structured state-space baselines. Relative to Transformer-based models, LiQSS achieves up to a 155x reduction in parameter count and up to 2.74x faster inference, without sacrificing forecasting accuracy.
Towards Bridging the FL Performance-Explainability Trade-Off: A Trustworthy 6G RAN Slicing Use-Case
Jul 24, 2023



In the context of sixth-generation (6G) networks, where diverse network slices coexist, the adoption of AI-driven zero-touch management and orchestration (MANO) becomes crucial. However, ensuring the trustworthiness of AI black-boxes in real deployments is challenging. Explainable AI (XAI) tools can play a vital role in establishing transparency among the stakeholders in the slicing ecosystem. But there is a trade-off between AI performance and explainability, posing a dilemma for trustworthy 6G network slicing because the stakeholders require both highly performing AI models for efficient resource allocation and explainable decision-making to ensure fairness, accountability, and compliance. To balance this trade off and inspired by the closed loop automation and XAI methodologies, this paper presents a novel explanation-guided in-hoc federated learning (FL) approach where a constrained resource allocation model and an explainer exchange -- in a closed loop (CL) fashion -- soft attributions of the features as well as inference predictions to achieve a transparent 6G network slicing resource management in a RAN-Edge setup under non-independent identically distributed (non-IID) datasets. In particular, we quantitatively validate the faithfulness of the explanations via the so-called attribution-based confidence metric that is included as a constraint to guide the overall training process in the run-time FL optimization task. In this respect, Integrated-Gradient (IG) as well as Input $\times$ Gradient and SHAP are used to generate the attributions for our proposed in-hoc scheme, wherefore simulation results under different methods confirm its success in tackling the performance-explainability trade-off and its superiority over the unconstrained Integrated-Gradient post-hoc FL baseline.
Explanation-Guided Fair Federated Learning for Transparent 6G RAN Slicing
Jul 18, 2023Future zero-touch artificial intelligence (AI)-driven 6G network automation requires building trust in the AI black boxes via explainable artificial intelligence (XAI), where it is expected that AI faithfulness would be a quantifiable service-level agreement (SLA) metric along with telecommunications key performance indicators (KPIs). This entails exploiting the XAI outputs to generate transparent and unbiased deep neural networks (DNNs). Motivated by closed-loop (CL) automation and explanation-guided learning (EGL), we design an explanation-guided federated learning (EGFL) scheme to ensure trustworthy predictions by exploiting the model explanation emanating from XAI strategies during the training run time via Jensen-Shannon (JS) divergence. Specifically, we predict per-slice RAN dropped traffic probability to exemplify the proposed concept while respecting fairness goals formulated in terms of the recall metric which is included as a constraint in the optimization task. Finally, the comprehensiveness score is adopted to measure and validate the faithfulness of the explanations quantitatively. Simulation results show that the proposed EGFL-JS scheme has achieved more than $50\%$ increase in terms of comprehensiveness compared to different baselines from the literature, especially the variant EGFL-KL that is based on the Kullback-Leibler Divergence. It has also improved the recall score with more than $25\%$ relatively to unconstrained-EGFL.
SliceOps: Explainable MLOps for Streamlined Automation-Native 6G Networks
Jul 04, 2023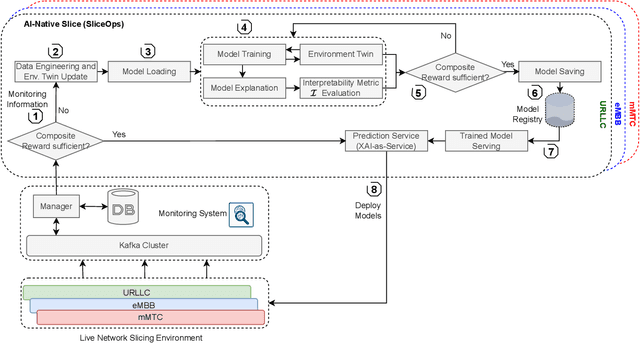
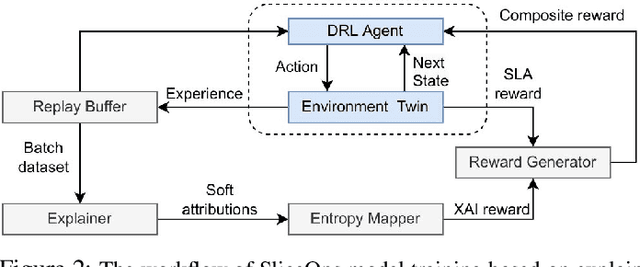
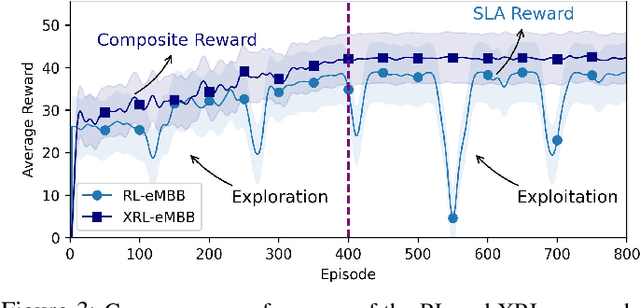
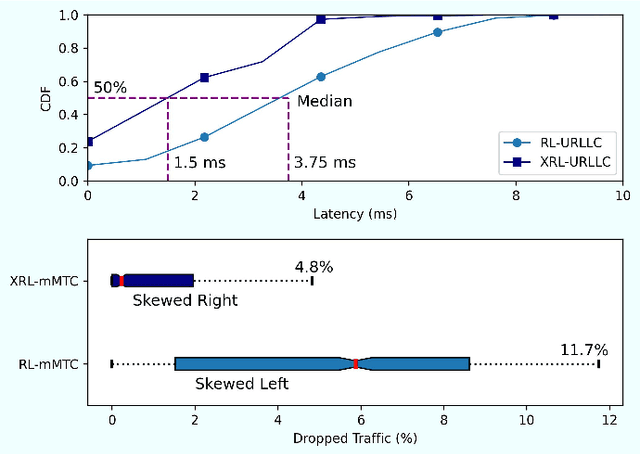
Sixth-generation (6G) network slicing is the backbone of future communications systems. It inaugurates the era of extreme ultra-reliable and low-latency communication (xURLLC) and pervades the digitalization of the various vertical immersive use cases. Since 6G inherently underpins artificial intelligence (AI), we propose a systematic and standalone slice termed SliceOps that is natively embedded in the 6G architecture, which gathers and manages the whole AI lifecycle through monitoring, re-training, and deploying the machine learning (ML) models as a service for the 6G slices. By leveraging machine learning operations (MLOps) in conjunction with eXplainable AI (XAI), SliceOps strives to cope with the opaqueness of black-box AI using explanation-guided reinforcement learning (XRL) to fulfill transparency, trustworthiness, and interpretability in the network slicing ecosystem. This article starts by elaborating on the architectural and algorithmic aspects of SliceOps. Then, the deployed cloud-native SliceOps working is exemplified via a latency-aware resource allocation problem. The deep RL (DRL)-based SliceOps agents within slices provide AI services aiming to allocate optimal radio resources and impede service quality degradation. Simulation results demonstrate the effectiveness of SliceOps-driven slicing. The article discusses afterward the SliceOps challenges and limitations. Finally, the key open research directions corresponding to the proposed approach are identified.
TEFL: Turbo Explainable Federated Learning for 6G Trustworthy Zero-Touch Network Slicing
Oct 18, 2022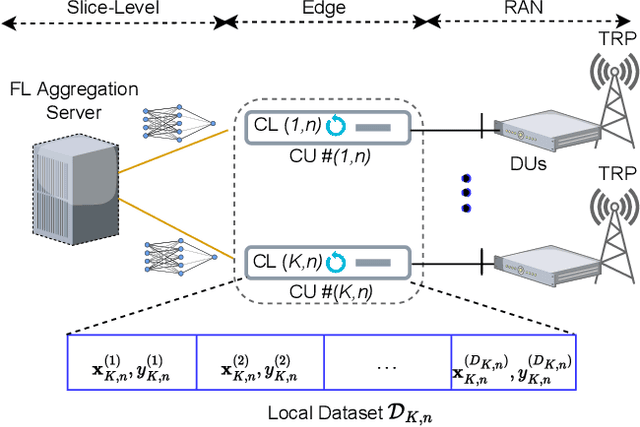
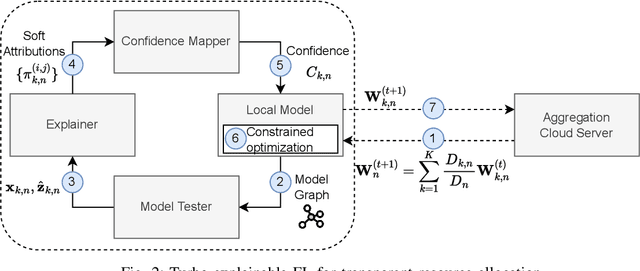
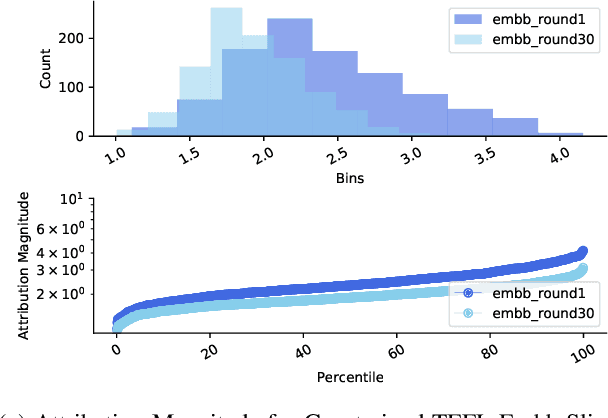
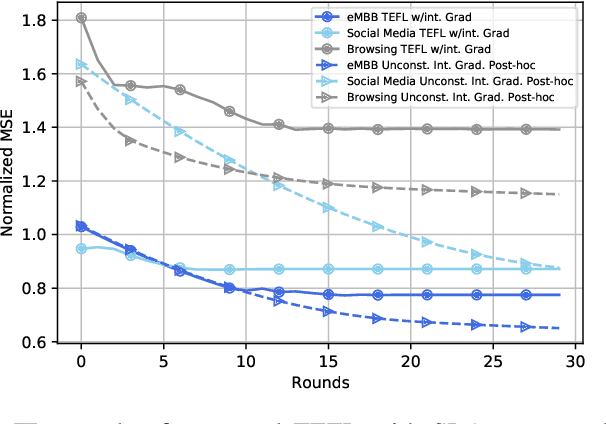
Sixth-generation (6G) networks anticipate intelligently supporting a massive number of coexisting and heterogeneous slices associated with various vertical use cases. Such a context urges the adoption of artificial intelligence (AI)-driven zero-touch management and orchestration (MANO) of the end-to-end (E2E) slices under stringent service level agreements (SLAs). Specifically, the trustworthiness of the AI black-boxes in real deployment can be achieved by explainable AI (XAI) tools to build transparency between the interacting actors in the slicing ecosystem, such as tenants, infrastructure providers and operators. Inspired by the turbo principle, this paper presents a novel iterative explainable federated learning (FL) approach where a constrained resource allocation model and an \emph{explainer} exchange -- in a closed loop (CL) fashion -- soft attributions of the features as well as inference predictions to achieve a transparent and SLA-aware zero-touch service management (ZSM) of 6G network slices at RAN-Edge setup under non-independent identically distributed (non-IID) datasets. In particular, we quantitatively validate the faithfulness of the explanations via the so-called attribution-based \emph{confidence metric} that is included as a constraint in the run-time FL optimization task. In this respect, Integrated-Gradient (IG) as well as Input $\times$ Gradient and SHAP are used to generate the attributions for the turbo explainable FL (TEFL), wherefore simulation results under different methods confirm its superiority over an unconstrained Integrated-Gradient \emph{post-hoc} FL baseline.