 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamRaz: A Culture-Based Persian Conversation Dataset for Person-Centered Therapy Using LLM Agents
Feb 09, 2025



This paper presents HamRaz, a novel Persian-language mental health dataset designed for Person-Centered Therapy (PCT) using Large Language Models (LLMs). Despite the growing application of LLMs in AI-driven psychological counseling, existing datasets predominantly focus on Western and East Asian contexts, overlooking cultural and linguistic nuances essential for effective Persian-language therapy. To address this gap, HamRaz combines script-based dialogues with adaptive LLM role-playing, ensuring coherent and dynamic therapy interactions. We also introduce HamRazEval, a dual evaluation framework that measures conversational quality and therapeutic effectiveness using General Dialogue Metrics and the Barrett-Lennard Relationship Inventory (BLRI). Experimental results show HamRaz outperforms conventional Script Mode and Two-Agent Mode, producing more empathetic, context-aware, and realistic therapy sessions. By releasing HamRaz, we contribute a culturally adapted, LLM-driven resource to advance AI-powered psychotherapy research in diverse communities.
PsychoLex: Unveiling the Psychological Mind of Large Language Models
Aug 16, 2024This paper explores the intersection of psychology and artificial intelligence through the development and evaluation of specialized Large Language Models (LLMs). We introduce PsychoLex, a suite of resources designed to enhance LLMs' proficiency in psychological tasks in both Persian and English. Key contributions include the PsychoLexQA dataset for instructional content and the PsychoLexEval dataset for rigorous evaluation of LLMs in complex psychological scenarios. Additionally, we present the PsychoLexLLaMA model, optimized specifically for psychological applications, demonstrating superior performance compared to general-purpose models. The findings underscore the potential of tailored LLMs for advancing psychological research and applications, while also highlighting areas for further refinement. This research offers a foundational step towards integrating LLMs into specialized psychological domains, with implications for future advancements in AI-driven psychological practice.
PersianLLaMA: Towards Building First Persian Large Language Model
Dec 25, 2023Despite the widespread use of the Persian language by millions globally, limited efforts have been made in natural language processing for this language. The use of large language models as effective tools in various natural language processing tasks typically requires extensive textual data and robust hardware resources. Consequently, the scarcity of Persian textual data and the unavailability of powerful hardware resources have hindered the development of large language models for Persian. This paper introduces the first large Persian language model, named PersianLLaMA, trained on a collection of Persian texts and datasets. This foundational model comes in two versions, with 7 and 13 billion parameters, trained on formal and colloquial Persian texts using two different approaches. PersianLLaMA has been evaluated for natural language generation tasks based on the latest evaluation methods, namely using larger language models, and for natural language understanding tasks based on automated machine metrics. The results indicate that PersianLLaMA significantly outperforms its competitors in both understanding and generating Persian text. PersianLLaMA marks an important step in the development of Persian natural language processing and can be a valuable resource for the Persian-speaking community. This large language model can be used for various natural language processing tasks, especially text generation like chatbots, question-answering, machine translation, and text summarization
Improving Fuzzy-Logic based Map-Matching Method with Trajectory Stay-Point Detection
Aug 04, 2022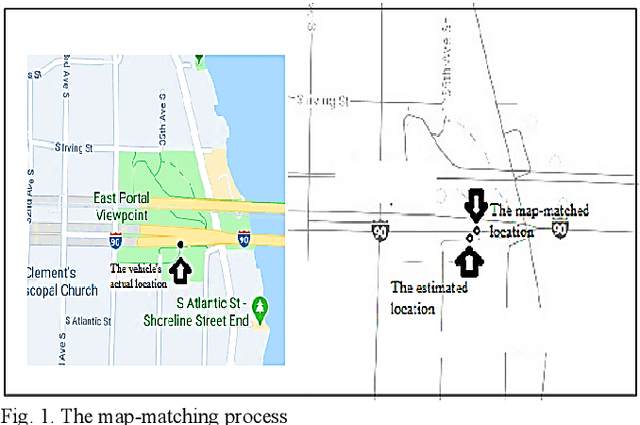
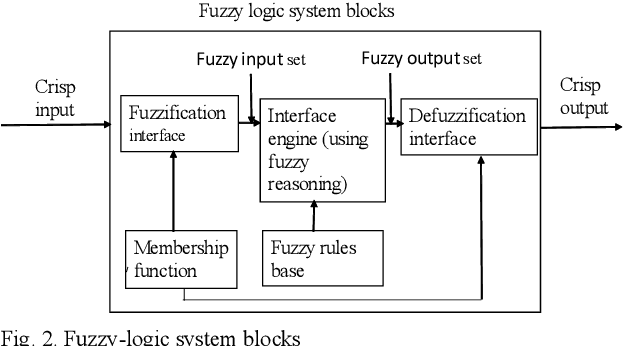
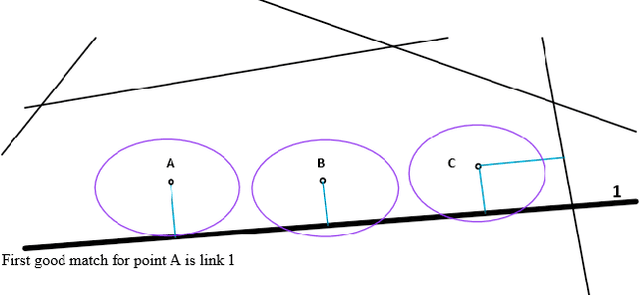
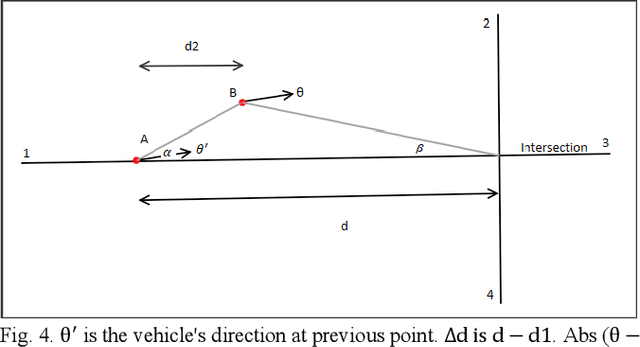
The requirement to trace and process moving objects in the contemporary era gradually increases since numerous applications quickly demand precise moving object locations. The Map-matching method is employed as a preprocessing technique, which matches a moving object point on a corresponding road. However, most of the GPS trajectory datasets include stay-points irregularity, which makes map-matching algorithms mismatch trajectories to irrelevant streets. Therefore, determining the stay-point region in GPS trajectory datasets results in better accurate matching and more rapid approaches. In this work, we cluster stay-points in a trajectory dataset with DBSCAN and eliminate redundant data to improve the efficiency of the map-matching algorithm by lowering processing time. We reckoned our proposed method's performance and exactness with a ground truth dataset compared to a fuzzy-logic based map-matching algorithm. Fortunately, our approach yields 27.39% data size reduction and 8.9% processing time reduction with the same accurate results as the previous fuzzy-logic based map-matching approach.