 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGRWO-Sampling: A modified random walk under-sampling approach based on graphs to imbalanced data classification
Feb 10, 2020



In this paper, we propose a new RWO-Sampling (Random Walk Over-Sampling) based on graphs for imbalanced datasets. In this method, two figures based on under-sampling and over-sampling methods are introduced to keep the proximity information, which is robust to noises and outliers. After the construction of the first graph on minority class, RWO-Sampling will be implemented on selected samples, and the rest of them will remain unchanged. The second graph is constructed for the majority class, and the samples in a low-density area (outliers) are removed. In the proposed method, examples of the majority class in a high-density area are selected, and the rest of them are eliminated. Furthermore, utilizing RWO-sampling, the boundary of minority class is increased though, the outliers are not raised. This method is tested, and the number of evaluation measures is compared to previous methods on nine continuous attribute datasets with different over-sampling rates. The experimental results were an indicator of the high efficiency and flexibility of the proposed method for the classification of imbalanced data.
Weighted second-order cone programming twin support vector machine for imbalanced data classification
Apr 26, 2019


We propose a method of using a Weighted second-order cone programming twin support vector machine (WSOCP-TWSVM) for imbalanced data classification. This method constructs a graph based under-sampling method which is utilized to remove outliers and reduce the dispensable majority samples. Then, appropriate weights are set in order to decrease the impact of samples of the majority class and increase the effect of the minority class in the optimization formula of the classifier. These weights are embedded in the optimization problem of the Second Order Cone Programming (SOCP) Twin Support Vector Machine formulations. This method is tested, and its performance is compared to previous methods on standard datasets. Results of experiments confirm the feasibility and efficiency of the proposed method.
QLMC-HD: Quasi Large Margin Classifier based on Hyperdisk
Mar 07, 2019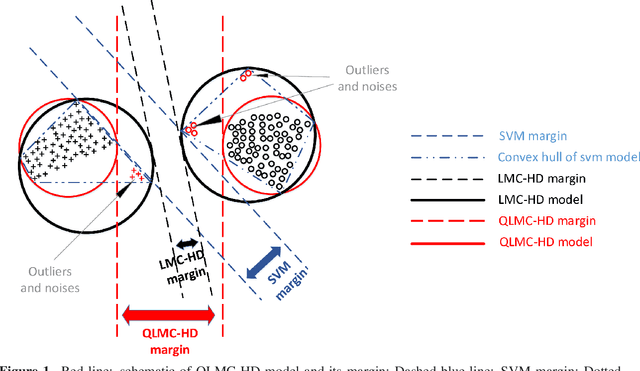



In the area of data classification, the different classifiers have been developed by its own strengths and weaknesses. Among these classifiers, we propose a method which is based on the maximum margin between two classes. One of the main challenges in this area is dealt with noisy data. In this paper, our aim is to optimize the method of large margin classifier based on hyperdisk (LMC-HD) and incorporate it into quasi-support vector data description (QSVDD) method. In the proposed method, the bounding hypersphere is calculated based on the QSVDD method. So our convex class model is more robust compared with support vector machine (SVM) and less tight than LMC-HD. Large margin classifiers aim to maximize the margin and minimizing the risk. Sine our proposed method ignores the effect of outliers and noises, so this method has the widest margin compared with other large margin classifiers. In the end, we compare our proposed method with other popular large margin classifiers by the experiments on a set of standard data which indicates our results are more efficient than the others.