 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decade of Wheat Mapping for Lebanon
Apr 15, 2025Wheat accounts for approximately 20% of the world's caloric intake, making it a vital component of global food security. Given this importance, mapping wheat fields plays a crucial role in enabling various stakeholders, including policy makers, researchers, and agricultural organizations, to make informed decisions regarding food security, supply chain management, and resource allocation. In this paper, we tackle the problem of accurately mapping wheat fields out of satellite images by introducing an improved pipeline for winter wheat segmentation, as well as presenting a case study on a decade-long analysis of wheat mapping in Lebanon. We integrate a Temporal Spatial Vision Transformer (TSViT) with Parameter-Efficient Fine Tuning (PEFT) and a novel post-processing pipeline based on the Fields of The World (FTW) framework. Our proposed pipeline addresses key challenges encountered in existing approaches, such as the clustering of small agricultural parcels in a single large field. By merging wheat segmentation with precise field boundary extraction, our method produces geometrically coherent and semantically rich maps that enable us to perform in-depth analysis such as tracking crop rotation pattern over years. Extensive evaluations demonstrate improved boundary delineation and field-level precision, establishing the potential of the proposed framework in operational agricultural monitoring and historical trend analysis. By allowing for accurate mapping of wheat fields, this work lays the foundation for a range of critical studies and future advances, including crop monitoring and yield estimation.
Efficient Adaptation For Remote Sensing Visual Grounding
Mar 29, 2025



Foundation models have revolutionized artificial intelligence (AI), offering remarkable capabilities across multi-modal domains. Their ability to precisely locate objects in complex aerial and satellite images, using rich contextual information and detailed object descriptions, is essential for remote sensing (RS). These models can associate textual descriptions with object positions through the Visual Grounding (VG) task, but due to domain-specific challenges, their direct application to RS produces sub-optimal results. To address this, we applied Parameter Efficient Fine Tuning (PEFT) techniques to adapt these models for RS-specific VG tasks. Specifically, we evaluated LoRA placement across different modules in Grounding DINO and used BitFit and adapters to fine-tune the OFA foundation model pre-trained on general-purpose VG datasets. This approach achieved performance comparable to or surpassing current State Of The Art (SOTA) models while significantly reducing computational costs. This study highlights the potential of PEFT techniques to advance efficient and precise multi-modal analysis in RS, offering a practical and cost-effective alternative to full model training.
Automated National Urban Map Extraction
Apr 09, 2024



Developing countries usually lack the proper governance means to generate and regularly update a national rooftop map. Using traditional photogrammetry and surveying methods to produce a building map at the federal level is costly and time consuming. Using earth observation and deep learning methods, we can bridge this gap and propose an automated pipeline to fetch such national urban maps. This paper aims to exploit the power of fully convolutional neural networks for multi-class buildings' instance segmentation to leverage high object-wise accuracy results. Buildings' instance segmentation from sub-meter high-resolution satellite images can be achieved with relatively high pixel-wise metric scores. We detail all engineering steps to replicate this work and ensure highly accurate results in dense and slum areas witnessed in regions that lack proper urban planning in the Global South. We applied a case study of the proposed pipeline to Lebanon and successfully produced the first comprehensive national building footprint map with approximately 1 Million units with an 84% accuracy. The proposed architecture relies on advanced augmentation techniques to overcome dataset scarcity, which is often the case in developing countries.
Empirical Study of PEFT techniques for Winter Wheat Segmentation
Oct 03, 2023



Parameter Efficient Fine Tuning (PEFT) techniques have recently experienced significant growth and have been extensively employed to adapt large vision and language models to various domains, enabling satisfactory model performance with minimal computational needs. Despite these advances, more research has yet to delve into potential PEFT applications in real-life scenarios, particularly in the critical domains of remote sensing and crop monitoring. The diversity of climates across different regions and the need for comprehensive large-scale datasets have posed significant obstacles to accurately identify crop types across varying geographic locations and changing growing seasons. This study seeks to bridge this gap by comprehensively exploring the feasibility of cross-area and cross-year out-of-distribution generalization using the State-of-the-Art (SOTA) wheat crop monitoring model. The aim of this work is to explore PEFT approaches for crop monitoring. Specifically, we focus on adapting the SOTA TSViT model to address winter wheat field segmentation, a critical task for crop monitoring and food security. This adaptation process involves integrating different PEFT techniques, including BigFit, LoRA, Adaptformer, and prompt tuning. Using PEFT techniques, we achieved notable results comparable to those achieved using full fine-tuning methods while training only a mere 0.7% parameters of the whole TSViT architecture. The in-house labeled data-set, referred to as the Beqaa-Lebanon dataset, comprises high-quality annotated polygons for wheat and non-wheat classes with a total surface of 170 kmsq, over five consecutive years. Using Sentinel-2 images, our model achieved a 84% F1-score. We intend to publicly release the Lebanese winter wheat data set, code repository, and model weights.
Zero-Shot Refinement of Buildings' Segmentation Models using SAM
Oct 03, 2023Foundation models have excelled in various tasks but are often evaluated on general benchmarks. The adaptation of these models for specific domains, such as remote sensing imagery, remains an underexplored area. In remote sensing, precise building instance segmentation is vital for applications like urban planning. While Convolutional Neural Networks (CNNs) perform well, their generalization can be limited. For this aim, we present a novel approach to adapt foundation models to address existing models' generalization dropback. Among several models, our focus centers on the Segment Anything Model (SAM), a potent foundation model renowned for its prowess in class-agnostic image segmentation capabilities. We start by identifying the limitations of SAM, revealing its suboptimal performance when applied to remote sensing imagery. Moreover, SAM does not offer recognition abilities and thus fails to classify and tag localized objects. To address these limitations, we introduce different prompting strategies, including integrating a pre-trained CNN as a prompt generator. This novel approach augments SAM with recognition abilities, a first of its kind. We evaluated our method on three remote sensing datasets, including the WHU Buildings dataset, the Massachusetts Buildings dataset, and the AICrowd Mapping Challenge. For out-of-distribution performance on the WHU dataset, we achieve a 5.47% increase in IoU and a 4.81% improvement in F1-score. For in-distribution performance on the WHU dataset, we observe a 2.72% and 1.58% increase in True-Positive-IoU and True-Positive-F1 score, respectively. We intend to release our code repository, hoping to inspire further exploration of foundation models for domain-specific tasks within the remote sensing community.
Solar Potential Assessment using Multi-Class Buildings Segmentation from Aerial Images
Nov 22, 2021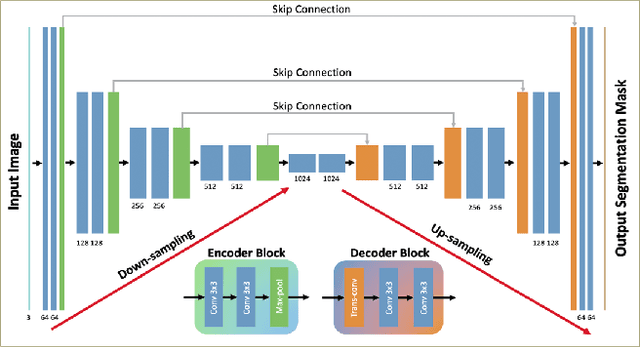
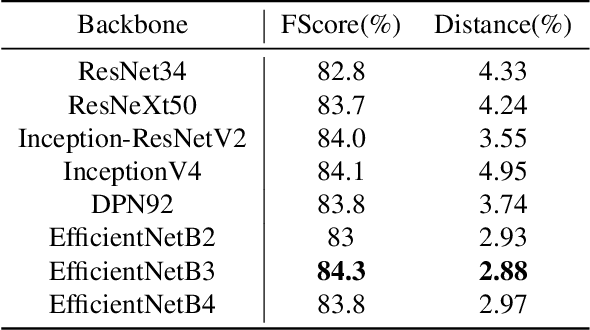
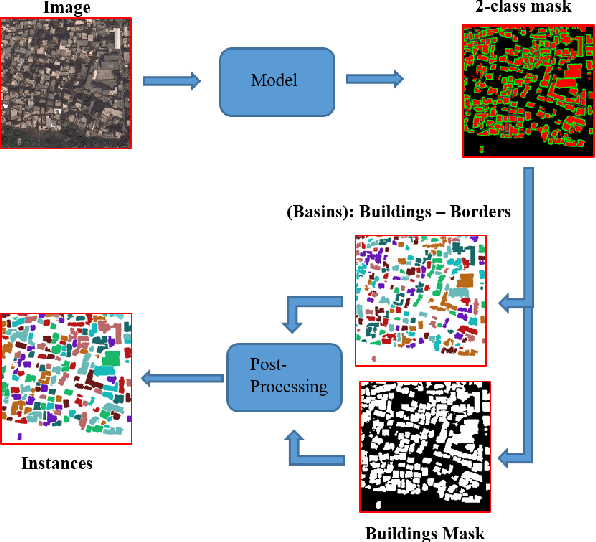
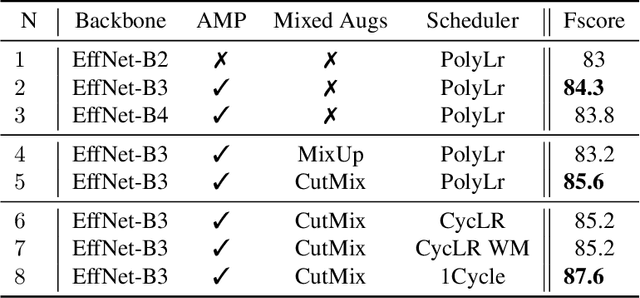
Semantic Segmentation of buildings present in satellite images using encoder-decoder like convolutional neural networks is being achieved with relatively high pixel-wise metric scores. In this paper, we aim to exploit the power of fully convolutional neural networks for an instance segmentation task using extra added classes to the output along with the watershed processing technique to leverage better object-wise metric results. We also show that CutMix mixed data augmentations and the One-Cycle learning rate policy are greater regularization methods to achieve a better fit on the training data and increase performance. Furthermore, Mixed Precision Training provided more flexibility to experiment with bigger networks and batches while maintaining stability and convergence during training. We compare and show the effect of these additional changes throughout our whole pipeline to finally provide a set a tuned hyper-parameters that are proven to perform better.
Sci-Net: a Scale Invariant Model for Building Detection from Aerial Images
Nov 18, 2021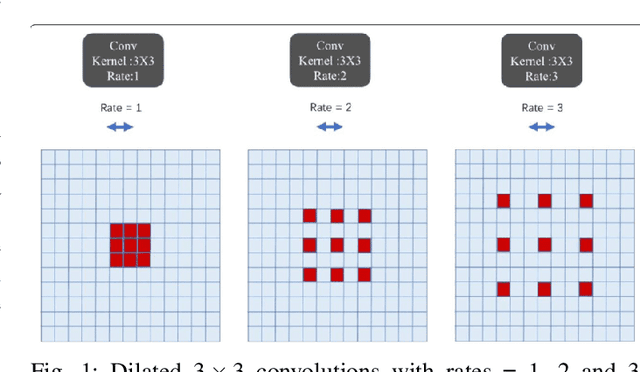
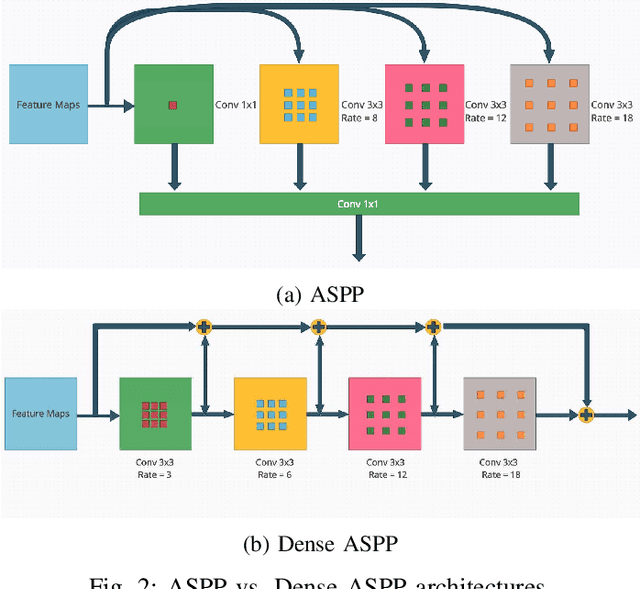
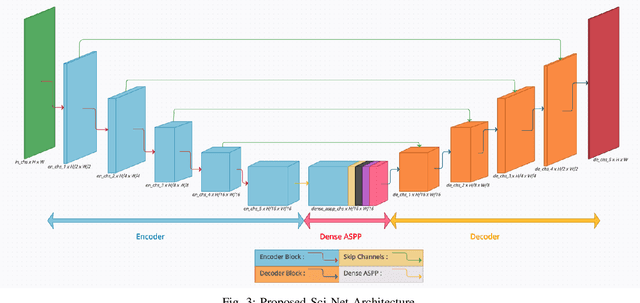
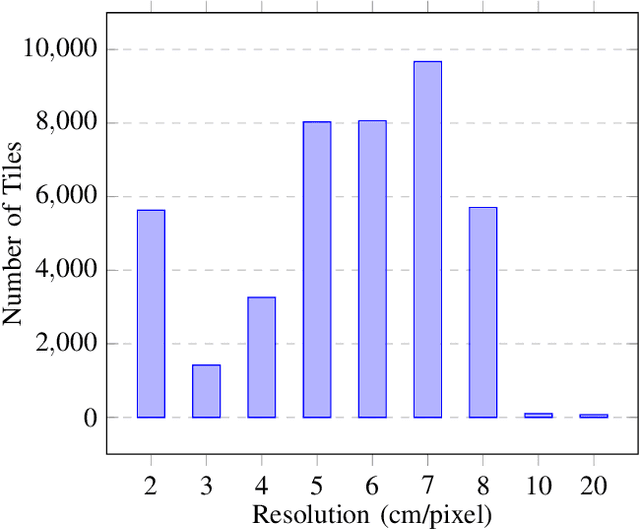
Buildings' segmentation is a fundamental task in the field of earth observation and aerial imagery analysis. Most existing deep learning based algorithms in the literature can be applied on fixed or narrow-ranged spatial resolution imagery. In practical scenarios, users deal with a wide spectrum of images resolution and thus, often need to resample a given aerial image to match the spatial resolution of the dataset used to train the deep learning model. This however, would result in a severe degradation in the quality of the output segmentation masks. To deal with this issue, we propose in this research a Scale-invariant neural network (Sci-Net) that is able to segment buildings present in aerial images at different spatial resolutions. Specifically, we modified the U-Net architecture and fused it with dense Atrous Spatial Pyramid Pooling (ASPP) to extract fine-grained multi-scale representations. We compared the performance of our proposed model against several state of the art models on the Open Cities AI dataset, and showed that Sci-Net provides a steady improvement margin in performance across all resolutions available in the dataset.