 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov-Smirnov Test-Based Actively-Adaptive Thompson Sampling for Non-Stationary Bandits
May 30, 2021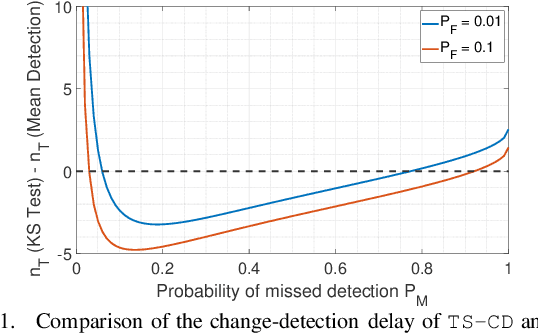
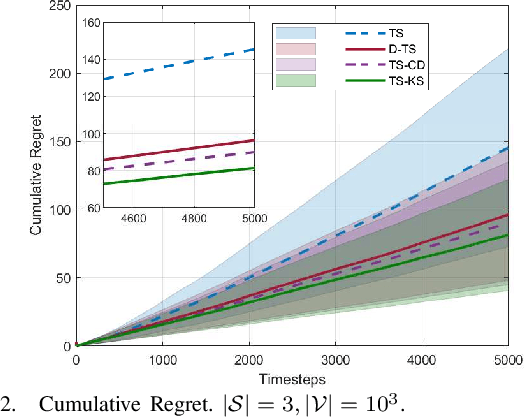
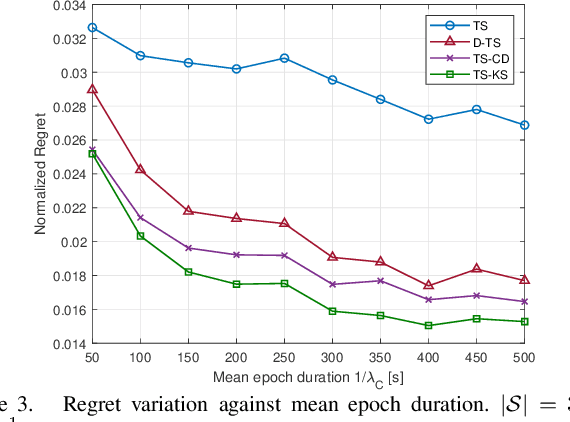
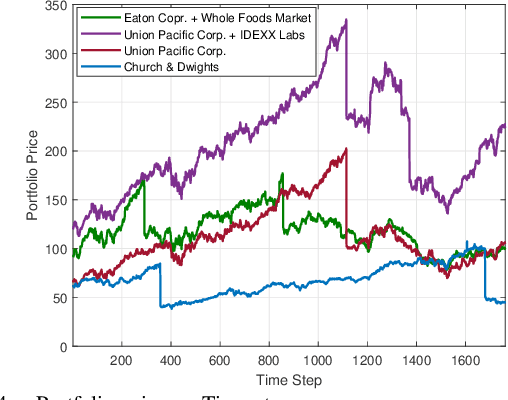
We consider the non-stationary multi-armed bandit (MAB) framework and propose a Kolmogorov-Smirnov (KS) test based Thompson Sampling (TS) algorithm named TS-KS, that actively detects change points and resets the TS parameters once a change is detected. In particular, for the two-armed bandit case, we derive bounds on the number of samples of the reward distribution to detect the change once it occurs. Consequently, we show that the proposed algorithm has sub-linear regret. Contrary to existing works, our algorithm is able to detect a change when the underlying reward distribution changes even though the mean reward remains the same. Finally, to test the efficacy of the proposed algorithm, we employ it in two case-studies: i) task-offloading scenario in wireless edge-computing, and ii) portfolio optimization. Our results show that the proposed TS-KS algorithm outperforms not only the static TS algorithm but also it performs better than other bandit algorithms designed for non-stationary environments. Moreover, the performance of TS-KS is at par with the state-of-the-art forecasting algorithms such as Facebook-PROPHET and ARIMA.