 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Position Aware Group Choreography using Large Language Model
Mar 12, 2025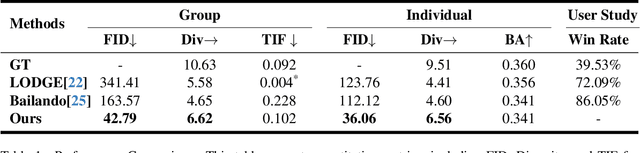
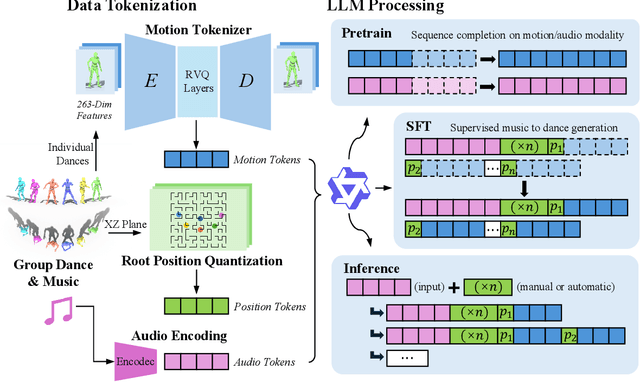
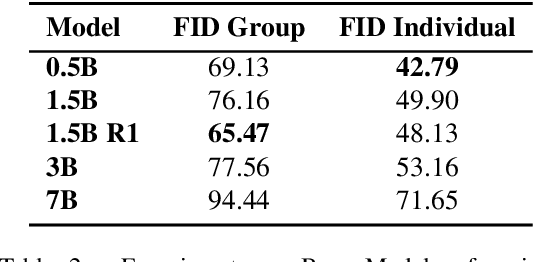
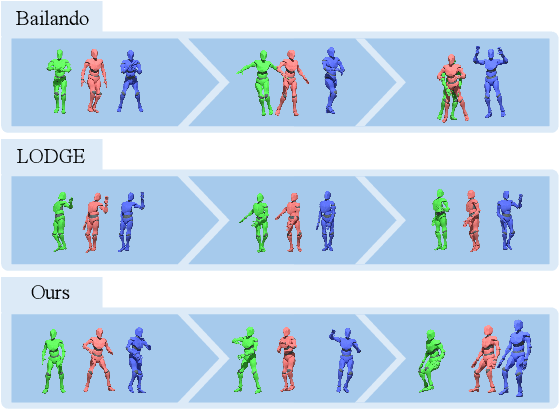
Dance serves as a profound and universal expression of human culture, conveying emotions and stories through movements synchronized with music. Although some current works have achieved satisfactory results in the task of single-person dance generation, the field of multi-person dance generation remains relatively novel. In this work, we present a group choreography framework that leverages recent advancements in Large Language Models (LLM) by modeling the group dance generation problem as a sequence-to-sequence translation task. Our framework consists of a tokenizer that transforms continuous features into discrete tokens, and an LLM that is fine-tuned to predict motion tokens given the audio tokens. We show that by proper tokenization of input modalities and careful design of the LLM training strategies, our framework can generate realistic and diverse group dances while maintaining strong music correlation and dancer-wise consistency. Extensive experiments and evaluations demonstrate that our framework achieves state-of-the-art performance.
LLM Gesticulator: Leveraging Large Language Models for Scalable and Controllable Co-Speech Gesture Synthesis
Oct 06, 2024In this work, we present LLM Gesticulator, an LLM-based audio-driven co-speech gesture generation framework that synthesizes full-body animations that are rhythmically aligned with the input audio while exhibiting natural movements and editability. Compared to previous work, our model demonstrates substantial scalability. As the size of the backbone LLM model increases, our framework shows proportional improvements in evaluation metrics (a.k.a. scaling law). Our method also exhibits strong controllability where the content, style of the generated gestures can be controlled by text prompt. To the best of our knowledge, LLM gesticulator is the first work that use LLM on the co-speech generation task. Evaluation with existing objective metrics and user studies indicate that our framework outperforms prior works.