 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolution for Temporal Sound Localisation Task of ECCV Second Perception Test Challenge 2024
Sep 29, 2024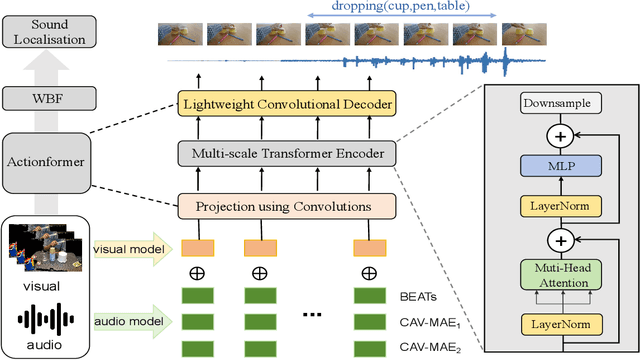
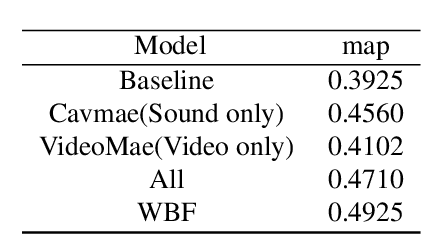
This report proposes an improved method for the Temporal Sound Localisation (TSL) task, which localizes and classifies the sound events occurring in the video according to a predefined set of sound classes. The champion solution from last year's first competition has explored the TSL by fusing audio and video modalities with the same weight. Considering the TSL task aims to localize sound events, we conduct relevant experiments that demonstrated the superiority of sound features (Section 3). Based on our findings, to enhance audio modality features, we employ various models to extract audio features, such as InterVideo, CaVMAE, and VideoMAE models. Our approach ranks first in the final test with a score of 0.4925.
Low-light Object Detection
May 06, 2024In this competition we employed a model fusion approach to achieve object detection results close to those of real images. Our method is based on the CO-DETR model, which was trained on two sets of data: one containing images under dark conditions and another containing images enhanced with low-light conditions. We used various enhancement techniques on the test data to generate multiple sets of prediction results. Finally, we applied a clustering aggregation method guided by IoU thresholds to select the optimal results.