 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitary Multi-Margin BERT for Robust Natural Language Processing
Oct 16, 2024



Recent developments in adversarial attacks on deep learning leave many mission-critical natural language processing (NLP) systems at risk of exploitation. To address the lack of computationally efficient adversarial defense methods, this paper reports a novel, universal technique that drastically improves the robustness of Bidirectional Encoder Representations from Transformers (BERT) by combining the unitary weights with the multi-margin loss. We discover that the marriage of these two simple ideas amplifies the protection against malicious interference. Our model, the unitary multi-margin BERT (UniBERT), boosts post-attack classification accuracies significantly by 5.3% to 73.8% while maintaining competitive pre-attack accuracies. Furthermore, the pre-attack and post-attack accuracy tradeoff can be adjusted via a single scalar parameter to best fit the design requirements for the target applications.
Deep Convolutional Neural Networks with Unitary Weights
Feb 23, 2021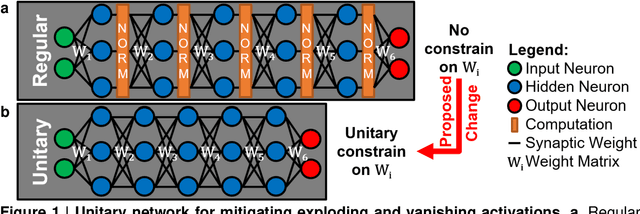
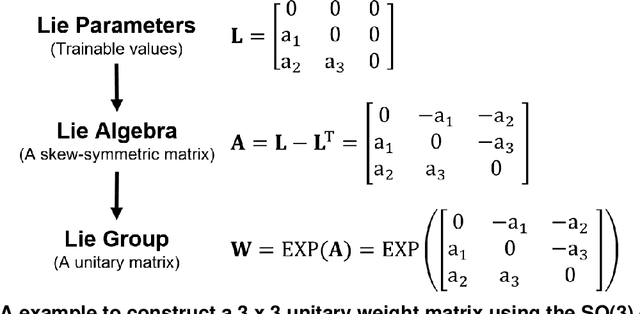
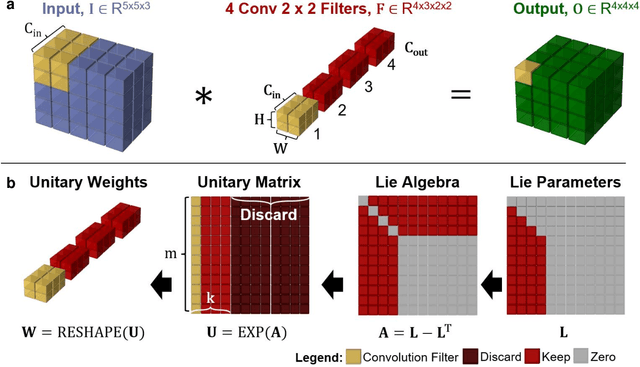
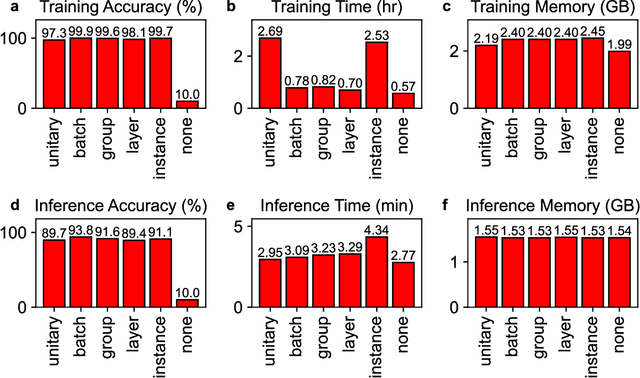
While normalizations aim to fix the exploding and vanishing gradient problem in deep neural networks, they have drawbacks in speed or accuracy because of their dependency on the data set statistics. This work is a comprehensive study of a novel method based on unitary synaptic weights derived from Lie Group to construct intrinsically stable neural systems. Here we show that unitary convolutional neural networks deliver up to 32% faster inference speeds while maintaining competitive prediction accuracy. Unlike prior arts restricted to square synaptic weights, we expand the unitary networks to weights of any size and dimension.
A Projection Algorithm for the Unitary Weights
Feb 19, 2021



Unitary neural networks are promising alternatives for solving the exploding and vanishing activation/gradient problem without the need for explicit normalization that reduces the inference speed. However, they often require longer training time due to the additional unitary constraints on their weight matrices. Here we show a novel algorithm using a backpropagation technique with Lie algebra for computing approximated unitary weights from their pre-trained, non-unitary counterparts. The unitary networks initialized with these approximations can reach the desired accuracies much faster, mitigating their training time penalties while maintaining inference speedups. Our approach will be instrumental in the adaptation of unitary networks, especially for those neural architectures where pre-trained weights are freely available.