 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabaek: High-performance water segmentation through dataset expansion and inductive bias optimization
Oct 21, 2024Water segmentation is critical to disaster response and water resource management. Authorities may employ high-resolution photography to monitor rivers, lakes, and reservoirs, allowing for more proactive management in agriculture, industry, and conservation. Deep learning has improved flood monitoring by allowing models like CNNs, U-Nets, and transformers to handle large volumes of satellite and aerial data. However, these models usually have significant processing requirements, limiting their usage in real-time applications. This research proposes upgrading the SegFormer model for water segmentation by data augmentation with datasets such as ADE20K and RIWA to boost generalization. We examine how inductive bias affects attention-based models and discover that SegFormer performs better on bigger datasets. To further demonstrate the function of data augmentation, Low-Rank Adaptation (LoRA) is used to lower processing complexity while preserving accuracy. We show that the suggested Habaek model outperforms current models in segmentation, with an Intersection over Union (IoU) ranging from 0.91986 to 0.94397. In terms of F1-score, recall, accuracy, and precision, Habaek performs better than rival models, indicating its potential for real-world applications. This study highlights the need to enhance structures and include datasets for effective water segmentation.
Design of a novel Korean learning application for efficient pronunciation correction
May 04, 2022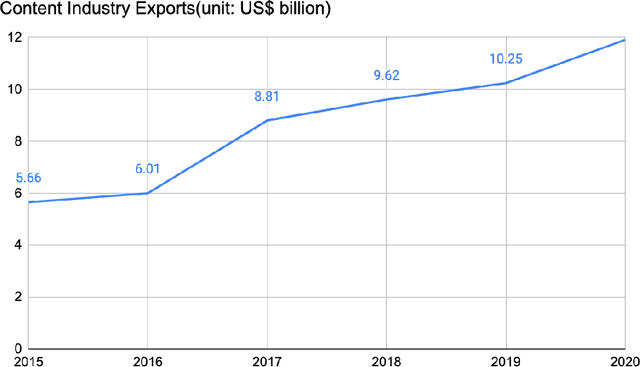
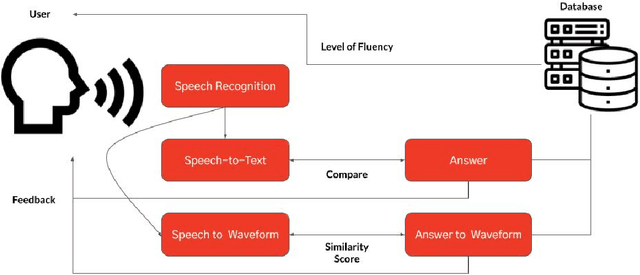
The Korean wave, which denotes the global popularity of South Korea's cultural economy, contributes to the increasing demand for the Korean language. However, as there does not exist any application for foreigners to learn Korean, this paper suggested a design of a novel Korean learning application. Speech recognition, speech-to-text, and speech-to-waveform are the three key systems in the proposed system. The Google API and the librosa library will transform the user's voice into a sentence and MFCC. The software will then display the user's phrase and answer, with mispronounced elements highlighted in red, allowing users to more easily recognize the incorrect parts of their pronunciation. Furthermore, the Siamese network might utilize those translated spectrograms to provide a similarity score, which could subsequently be used to offer feedback to the user. Despite the fact that we were unable to collect sufficient foreigner data for this research, it is notable that we presented a novel Korean pronunciation correction method for foreigners.