 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Dynamic and Sparse Qualitative Data: A Hilbert Space Embedding of Categorical Variables
Aug 22, 2023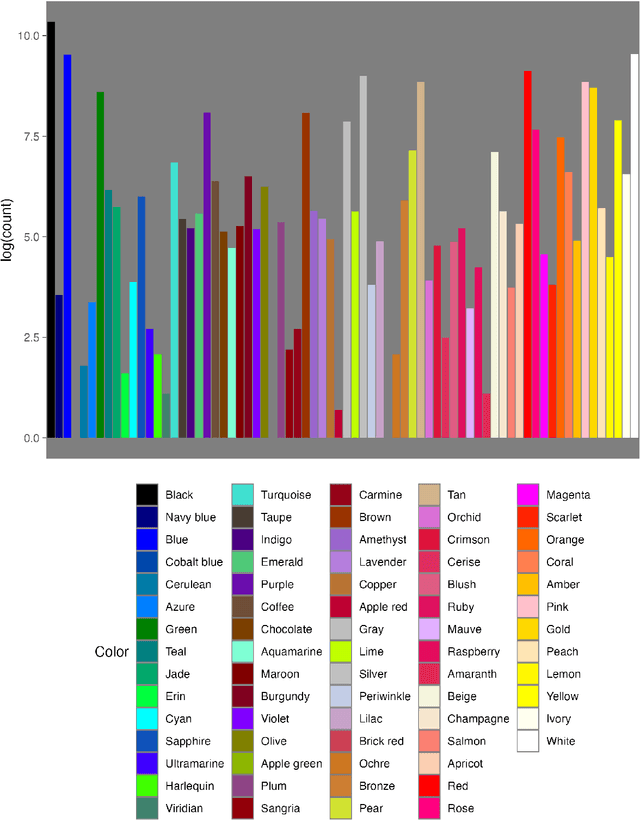
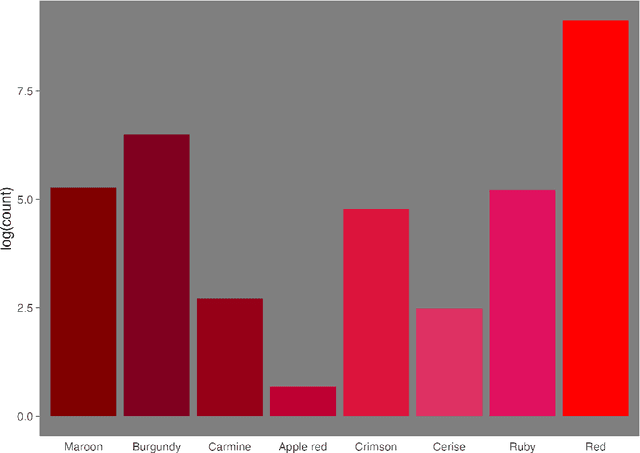
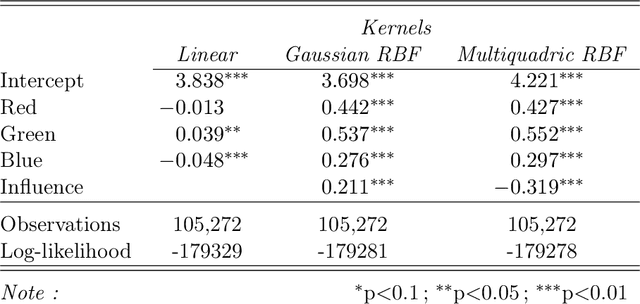
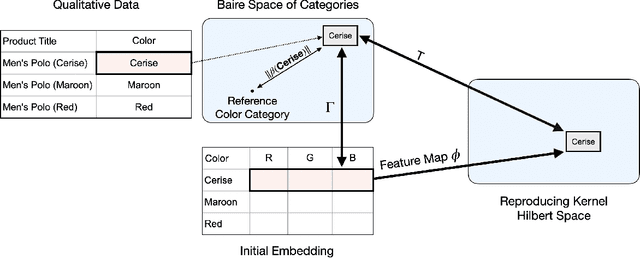
We propose a novel framework for incorporating qualitative data into quantitative models for causal estimation. Previous methods use categorical variables derived from qualitative data to build quantitative models. However, this approach can lead to data-sparse categories and yield inconsistent (asymptotically biased) and imprecise (finite sample biased) estimates if the qualitative information is dynamic and intricate. We use functional analysis to create a more nuanced and flexible framework. We embed the observed categories into a latent Baire space and introduce a continuous linear map -- a Hilbert space embedding -- from the Baire space of categories to a Reproducing Kernel Hilbert Space (RKHS) of representation functions. Through the Riesz representation theorem, we establish that the canonical treatment of categorical variables in causal models can be transformed into an identified structure in the RKHS. Transfer learning acts as a catalyst to streamline estimation -- embeddings from traditional models are paired with the kernel trick to form the Hilbert space embedding. We validate our model through comprehensive simulation evidence and demonstrate its relevance in a real-world study that contrasts theoretical predictions from economics and psychology in an e-commerce marketplace. The results confirm the superior performance of our model, particularly in scenarios where qualitative information is nuanced and complex.
Machine Learning and Consumer Data
Jun 25, 2023The digital revolution has led to the digitization of human behavior, creating unprecedented opportunities to understand observable actions on an unmatched scale. Emerging phenomena such as crowdfunding and crowdsourcing have further illuminated consumer behavior while also introducing new behavioral patterns. However, the sheer volume and complexity of this data present significant challenges for marketing researchers and practitioners. Traditional methods used to analyze consumer data fall short in handling the breadth, precision, and scale of emerging data sources. To address this, computational methods have been developed to manage the "big data" associated with consumer behavior, which typically includes structured data, textual data, audial data, and visual data. These methods, particularly machine learning, allow for effective parsing and processing of multi-faceted data. Given these recent developments, this review article seeks to familiarize researchers and practitioners with new data sources and analysis techniques for studying consumer behavior at scale. It serves as an introduction to the application of computational social science in understanding and leveraging publicly available consumer data.