 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mismeasure of Man and Models: Evaluating Allocational Harms in Large Language Models
Aug 02, 2024



Large language models (LLMs) are now being considered and even deployed for applications that support high-stakes decision-making, such as recruitment and clinical decisions. While several methods have been proposed for measuring bias, there remains a gap between predictions, which are what the proposed methods consider, and how they are used to make decisions. In this work, we introduce Rank-Allocational-Based Bias Index (RABBI), a model-agnostic bias measure that assesses potential allocational harms arising from biases in LLM predictions. We compare RABBI and current bias metrics on two allocation decision tasks. We evaluate their predictive validity across ten LLMs and utility for model selection. Our results reveal that commonly-used bias metrics based on average performance gap and distribution distance fail to reliably capture group disparities in allocation outcomes, whereas RABBI exhibits a strong correlation with allocation disparities. Our work highlights the need to account for how models are used in contexts with limited resource constraints.
Addressing Both Statistical and Causal Gender Fairness in NLP Models
Mar 30, 2024Statistical fairness stipulates equivalent outcomes for every protected group, whereas causal fairness prescribes that a model makes the same prediction for an individual regardless of their protected characteristics. Counterfactual data augmentation (CDA) is effective for reducing bias in NLP models, yet models trained with CDA are often evaluated only on metrics that are closely tied to the causal fairness notion; similarly, sampling-based methods designed to promote statistical fairness are rarely evaluated for causal fairness. In this work, we evaluate both statistical and causal debiasing methods for gender bias in NLP models, and find that while such methods are effective at reducing bias as measured by the targeted metric, they do not necessarily improve results on other bias metrics. We demonstrate that combinations of statistical and causal debiasing techniques are able to reduce bias measured through both types of metrics.
Finding Friends and Flipping Frenemies: Automatic Paraphrase Dataset Augmentation Using Graph Theory
Nov 03, 2020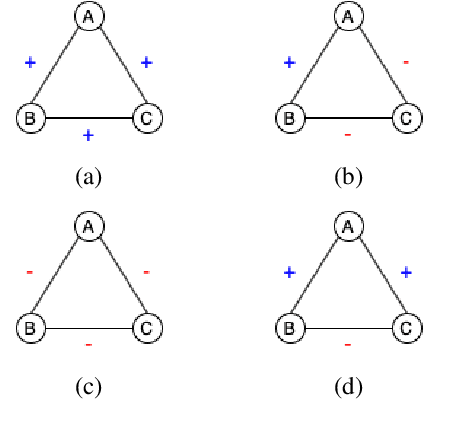
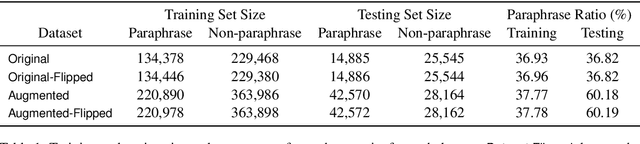
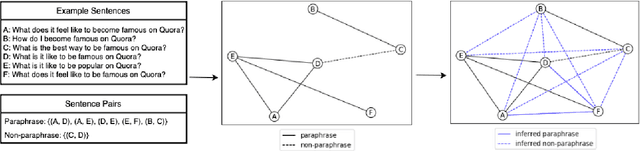
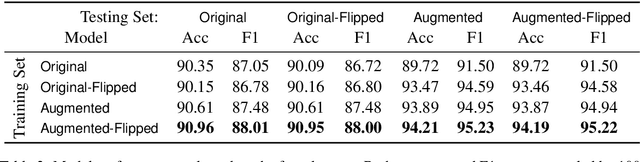
Most NLP datasets are manually labeled, so suffer from inconsistent labeling or limited size. We propose methods for automatically improving datasets by viewing them as graphs with expected semantic properties. We construct a paraphrase graph from the provided sentence pair labels, and create an augmented dataset by directly inferring labels from the original sentence pairs using a transitivity property. We use structural balance theory to identify likely mislabelings in the graph, and flip their labels. We evaluate our methods on paraphrase models trained using these datasets starting from a pretrained BERT model, and find that the automatically-enhanced training sets result in more accurate models.
Pointwise Paraphrase Appraisal is Potentially Problematic
Jun 05, 2020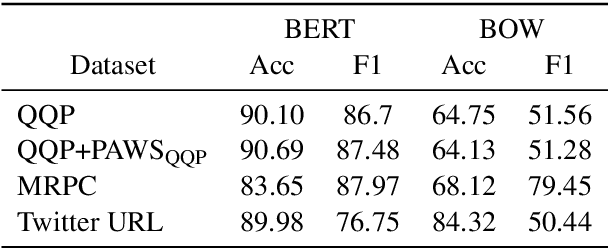

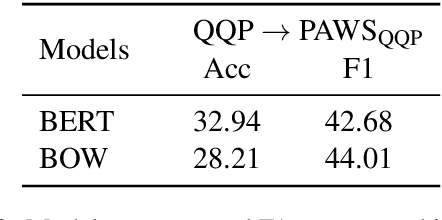
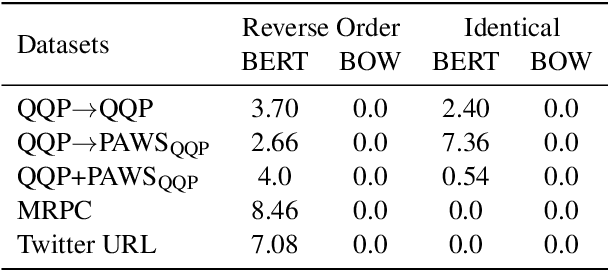
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.