 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs
Sep 09, 2019


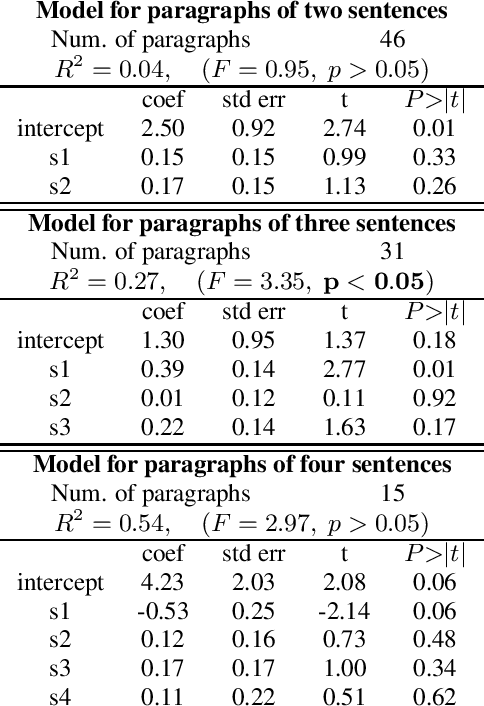
Text-to-speech systems are typically evaluated on single sentences. When long-form content, such as data consisting of full paragraphs or dialogues is considered, evaluating sentences in isolation is not always appropriate as the context in which the sentences are synthesized is missing. In this paper, we investigate three different ways of evaluating the naturalness of long-form text-to-speech synthesis. We compare the results obtained from evaluating sentences in isolation, evaluating whole paragraphs of speech, and presenting a selection of speech or text as context and evaluating the subsequent speech. We find that, even though these three evaluations are based upon the same material, the outcomes differ per setting, and moreover that these outcomes do not necessarily correlate with each other. We show that our findings are consistent between a single speaker setting of read paragraphs and a two-speaker dialogue scenario. We conclude that to evaluate the quality of long-form speech, the traditional way of evaluating sentences in isolation does not suffice, and that multiple evaluations are required.
Prosody Modifications for Question-Answering in Voice-Only Settings
Jun 11, 2018

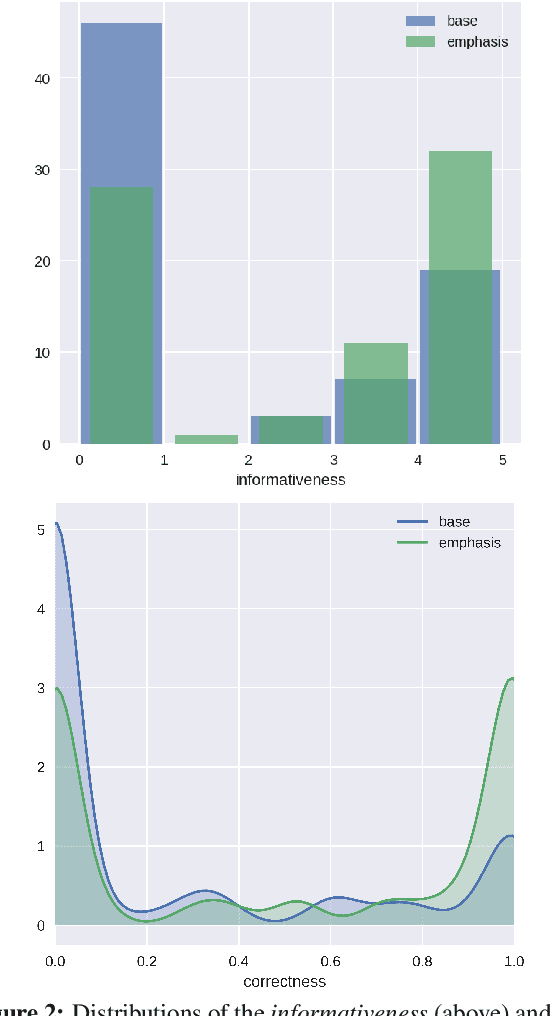

Many popular form factors of digital assistant---such as Amazon Echo, Apple Homepod or Google Home---enable the user to hold a conversation with the assistant based only on the speech modality. The lack of a screen from which the user can read text or watch supporting images or video presents unique challenges. In order to satisfy the information need of a user, we believe that the presentation of the answer needs to be optimized for such voice-only interactions. In this paper we propose a task of evaluating usefulness of prosody modifications for the purpose of voice-only question answering. We describe a crowd-sourcing setup where we evaluate the quality of these modifications along multiple dimensions corresponding to the informativeness, naturalness, and ability of the user to identify the key part of the answer. In addition, we propose a set of simple prosodic modifications that highlight important parts of the answer using various acoustic cues.