 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Prior to Court Legal Analysis: A Transparent and Accessible Dataset for Defensive Statement Classification and Interpretation
May 17, 2024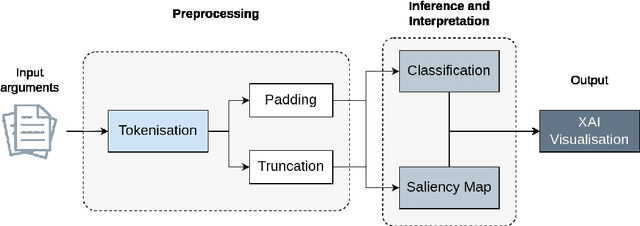
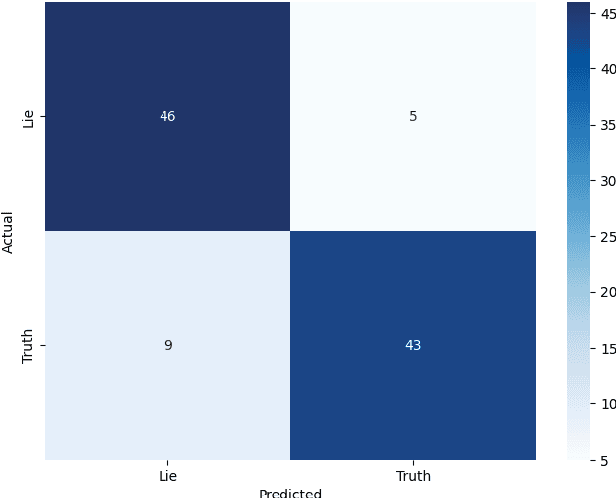
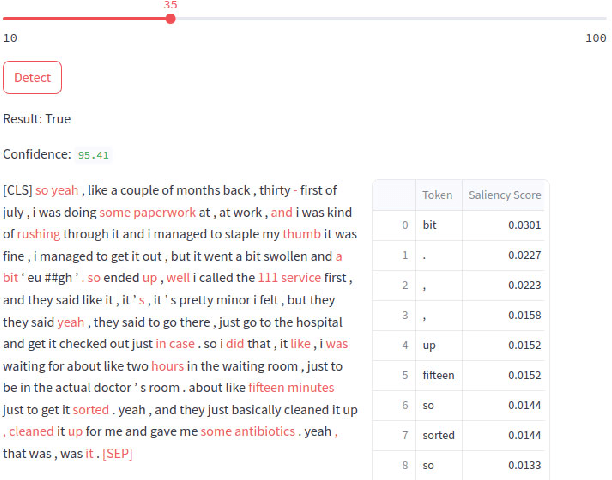
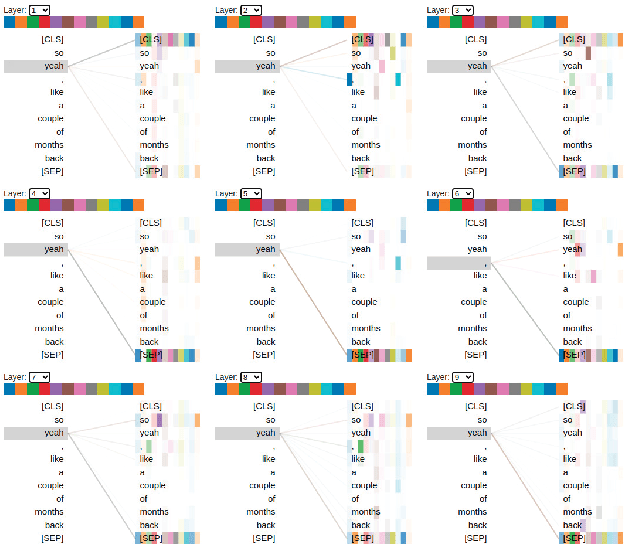
The classification of statements provided by individuals during police interviews is a complex and significant task within the domain of natural language processing (NLP) and legal informatics. The lack of extensive domain-specific datasets raises challenges to the advancement of NLP methods in the field. This paper aims to address some of the present challenges by introducing a novel dataset tailored for classification of statements made during police interviews, prior to court proceedings. Utilising the curated dataset for training and evaluation, we introduce a fine-tuned DistilBERT model that achieves state-of-the-art performance in distinguishing truthful from deceptive statements. To enhance interpretability, we employ explainable artificial intelligence (XAI) methods to offer explainability through saliency maps, that interpret the model's decision-making process. Lastly, we present an XAI interface that empowers both legal professionals and non-specialists to interact with and benefit from our system. Our model achieves an accuracy of 86%, and is shown to outperform a custom transformer architecture in a comparative study. This holistic approach advances the accessibility, transparency, and effectiveness of statement analysis, with promising implications for both legal practice and research.