 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Meta Federated Learning Framework with Theoretical Convergence Guarantees
Apr 30, 2025Meta federated learning (FL) is a personalized variant of FL, where multiple agents collaborate on training an initial shared model without exchanging raw data samples. The initial model should be trained in a way that current or new agents can easily adapt it to their local datasets after one or a few fine-tuning steps, thus improving the model personalization. Conventional meta FL approaches minimize the average loss of agents on the local models obtained after one step of fine-tuning. In practice, agents may need to apply several fine-tuning steps to adapt the global model to their local data, especially under highly heterogeneous data distributions across agents. To this end, we present a generalized framework for the meta FL by minimizing the average loss of agents on their local model after any arbitrary number $\nu$ of fine-tuning steps. For this generalized framework, we present a variant of the well-known federated averaging (FedAvg) algorithm and conduct a comprehensive theoretical convergence analysis to characterize the convergence speed as well as behavior of the meta loss functions in both the exact and approximated cases. Our experiments on real-world datasets demonstrate superior accuracy and faster convergence for the proposed scheme compared to conventional approaches.
ProductAE: Toward Deep Learning Driven Error-Correction Codes of Large Dimensions
Mar 29, 2023



While decades of theoretical research have led to the invention of several classes of error-correction codes, the design of such codes is an extremely challenging task, mostly driven by human ingenuity. Recent studies demonstrate that such designs can be effectively automated and accelerated via tools from machine learning (ML), thus enabling ML-driven classes of error-correction codes with promising performance gains compared to classical designs. A fundamental challenge, however, is that it is prohibitively complex, if not impossible, to design and train fully ML-driven encoder and decoder pairs for large code dimensions. In this paper, we propose Product Autoencoder (ProductAE) -- a computationally-efficient family of deep learning driven (encoder, decoder) pairs -- aimed at enabling the training of relatively large codes (both encoder and decoder) with a manageable training complexity. We build upon ideas from classical product codes and propose constructing large neural codes using smaller code components. ProductAE boils down the complex problem of training the encoder and decoder for a large code dimension $k$ and blocklength $n$ to less-complex sub-problems of training encoders and decoders for smaller dimensions and blocklengths. Our training results show successful training of ProductAEs of dimensions as large as $k = 300$ bits with meaningful performance gains compared to state-of-the-art classical and neural designs. Moreover, we demonstrate excellent robustness and adaptivity of ProductAEs to channel models different than the ones used for training.
List Autoencoder: Towards Deep Learning Based Reliable Transmission Over Noisy Channels
Dec 19, 2021


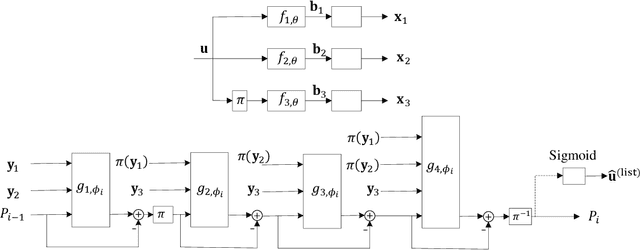
There has been a growing interest in automating the design of channel encoders and decoders in an auto-encoder(AE) framework in recent years for reliable transmission of data over noisy channels. In this paper we present a new framework for designing AEs for this purpose. In particular, we present an AE framework, namely listAE, in which the decoder network outputs a list of decoded message word candidates. A genie is assumed to be available at the output of the decoder and specific loss functions are proposed to optimize the performance of the genie-aided (GA)-listAE. The listAE is a general AE framework and can be used with any network architecture. We propose a specific end-to-end network architecture which decodes the received word on a sequence of component codes with decreasing rates. The listAE based on the proposed architecture, referred to as incremental redundancy listAE (IR-listAE), improves the state-of-the-art AE performance by 1 dB at low block error rates under GA decoding. We then employ cyclic redundancy check (CRC) codes to replace the genie at the decoder, giving CRC-aided (CA)-listAE with negligible performance loss compared to the GA-listAE. The CA-listAE shows meaningful coding gain at the price of a slight decrease in the rate due to appending CRC to the message word.
ProductAE: Towards Training Larger Channel Codes based on Neural Product Codes
Oct 09, 2021
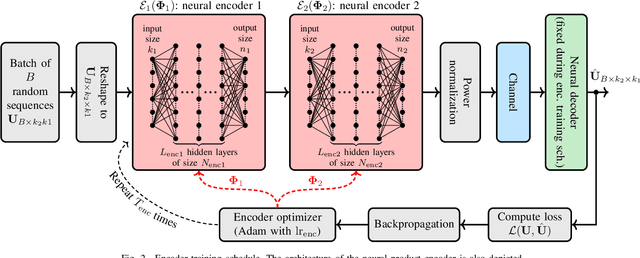
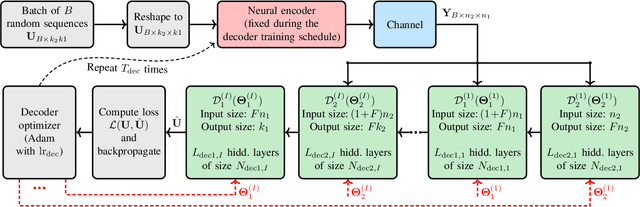
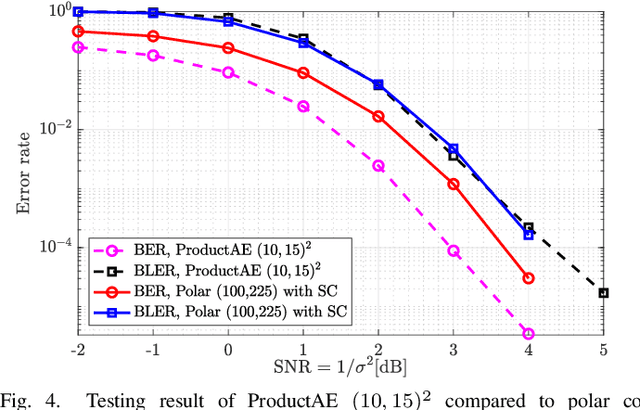
There have been significant research activities in recent years to automate the design of channel encoders and decoders via deep learning. Due the dimensionality challenge in channel coding, it is prohibitively complex to design and train relatively large neural channel codes via deep learning techniques. Consequently, most of the results in the literature are limited to relatively short codes having less than 100 information bits. In this paper, we construct ProductAEs, a computationally efficient family of deep-learning driven (encoder, decoder) pairs, that aim at enabling the training of relatively large channel codes (both encoders and decoders) with a manageable training complexity. We build upon the ideas from classical product codes, and propose constructing large neural codes using smaller code components. More specifically, instead of directly training the encoder and decoder for a large neural code of dimension $k$ and blocklength $n$, we provide a framework that requires training neural encoders and decoders for the code parameters $(k_1,n_1)$ and $(k_2,n_2)$ such that $k_1 k_2=k$ and $n_1 n_2=n$. Our training results show significant gains, over all ranges of signal-to-noise ratio (SNR), for a code of parameters $(100,225)$ and a moderate-length code of parameters $(196,441)$, over polar codes under successive cancellation (SC) decoder. Moreover, our results demonstrate meaningful gains over Turbo Autoencoder (TurboAE) and state-of-the-art classical codes. This is the first work to design product autoencoders and a pioneering work on training large channel codes.