 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Semantic Image Editing with Style Codes
Sep 25, 2023
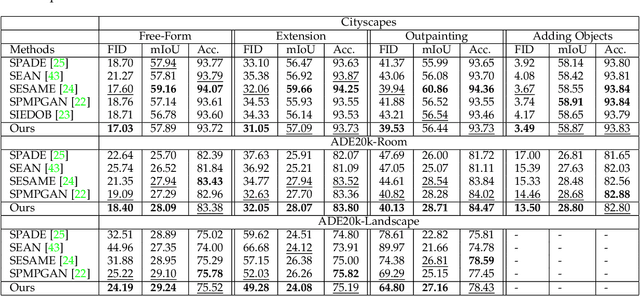


Semantic image editing requires inpainting pixels following a semantic map. It is a challenging task since this inpainting requires both harmony with the context and strict compliance with the semantic maps. The majority of the previous methods proposed for this task try to encode the whole information from erased images. However, when an object is added to a scene such as a car, its style cannot be encoded from the context alone. On the other hand, the models that can output diverse generations struggle to output images that have seamless boundaries between the generated and unerased parts. Additionally, previous methods do not have a mechanism to encode the styles of visible and partially visible objects differently for better performance. In this work, we propose a framework that can encode visible and partially visible objects with a novel mechanism to achieve consistency in the style encoding and final generations. We extensively compare with previous conditional image generation and semantic image editing algorithms. Our extensive experiments show that our method significantly improves over the state-of-the-art. Our method not only achieves better quantitative results but also provides diverse results. Please refer to the project web page for the released code and demo: https://github.com/hakansivuk/DivSem.