 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkIn: Skimming-Intensive Long-Text Classification Using BERT for Medical Corpus
Sep 24, 2022
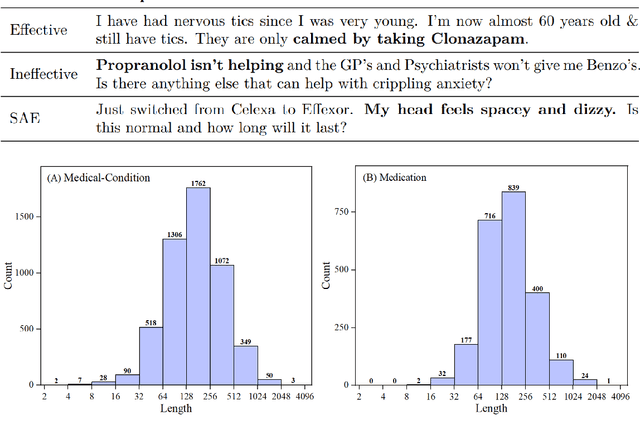
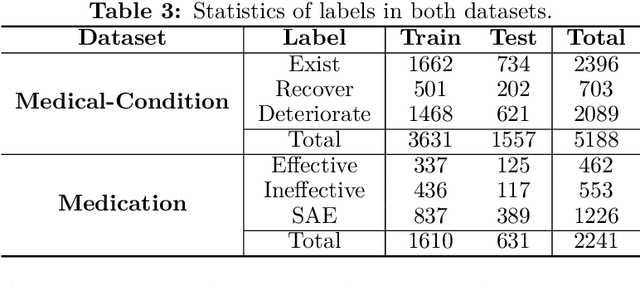
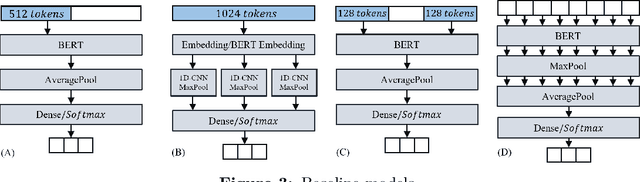
BERT is a widely used pre-trained model in natural language processing. However, since BERT is quadratic to the text length, the BERT model is difficult to be used directly on the long-text corpus. In some fields, the collected text data may be quite long, such as in the health care field. Therefore, to apply the pre-trained language knowledge of BERT to long text, in this paper, imitating the skimming-intensive reading method used by humans when reading a long paragraph, the Skimming-Intensive Model (SkIn) is proposed. It can dynamically select the critical information in the text so that the sentence input into the BERT-Base model is significantly shortened, which can effectively save the cost of the classification algorithm. Experiments show that the SkIn method has achieved superior accuracy than the baselines on long-text classification datasets in the medical field, while its time and space requirements increase linearly with the text length, alleviating the time and space overflow problem of basic BERT on long-text data.