 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Data Dispersion Degree in Automatic Robust Estimation for Multivariate Gaussian Mixture Models with an Application to Noisy Speech Processing
May 19, 2014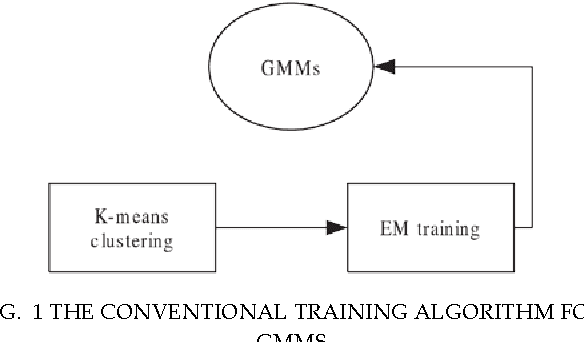

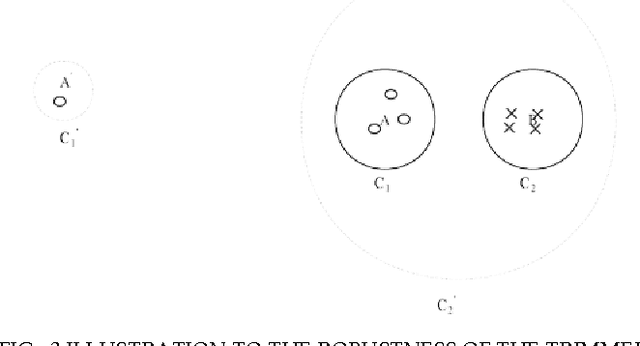

The trimming scheme with a prefixed cutoff portion is known as a method of improving the robustness of statistical models such as multivariate Gaussian mixture models (MG- MMs) in small scale tests by alleviating the impacts of outliers. However, when this method is applied to real- world data, such as noisy speech processing, it is hard to know the optimal cut-off portion to remove the outliers and sometimes removes useful data samples as well. In this paper, we propose a new method based on measuring the dispersion degree (DD) of the training data to avoid this problem, so as to realise automatic robust estimation for MGMMs. The DD model is studied by using two different measures. For each one, we theoretically prove that the DD of the data samples in a context of MGMMs approximately obeys a specific (chi or chi-square) distribution. The proposed method is evaluated on a real-world application with a moderately-sized speaker recognition task. Experiments show that the proposed method can significantly improve the robustness of the conventional training method of GMMs for speaker recognition.