 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ&A Prompts: Discovering Rich Visual Clues through Mining Question-Answer Prompts for VQA requiring Diverse World Knowledge
Jan 19, 2024
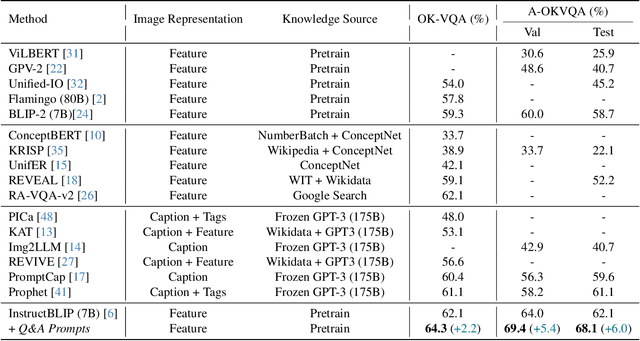


With the breakthrough of multi-modal large language models, answering complex visual questions that demand advanced reasoning abilities and world knowledge has become a much more important testbed for developing AI models than ever. However, equipping AI models with robust cross-modality reasoning ability remains challenging since the cognition scheme of humans has not been understood systematically. In this paper, we believe that if we can collect visual clues in the given image as much as possible, we will recognize the image more accurately, understand the question better, recall relevant knowledge more easily, and finally reason out the answer. We discover these rich visual clues by mining question-answer pairs in images and sending them into multi-modal large language models as prompts. We call the proposed method Q&A Prompts. Specifically, we first use the image-answer pairs and the corresponding questions in the training set as inputs and outputs to train a visual question generation model. Then, we use an image tagging model to identify various instances and send packaged image-tag pairs into the visual question generation model to generate relevant questions with the extracted image tags as answers. Finally, we encode these generated question-answer pairs as prompts with a visual-aware prompting module and send them into pre-trained multi-modal large language models to reason out the final answers. Experimental results show that, compared with state-of-the-art methods, our Q&A Prompts achieves substantial improvements on the challenging visual question answering datasets requiring reasoning over diverse world knowledge, such as OK-VQA and A-OKVQA.