 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLILE: Look In-Depth before Looking Elsewhere -- A Dual Attention Network using Transformers for Cross-Modal Information Retrieval in Histopathology Archives
Mar 04, 2022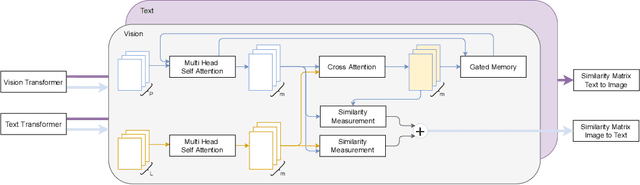
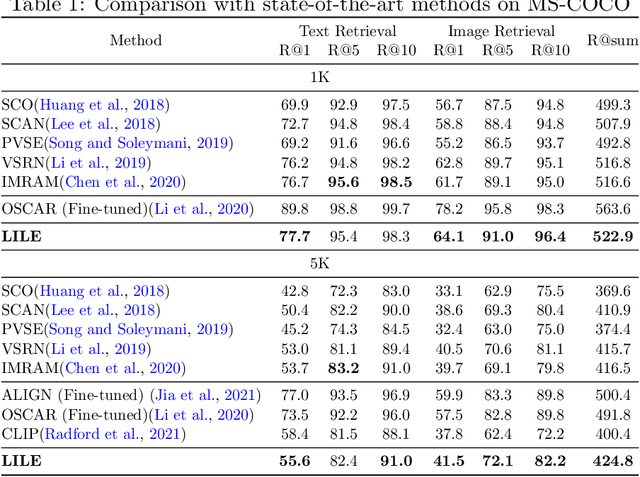
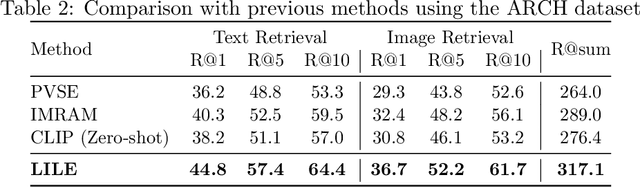
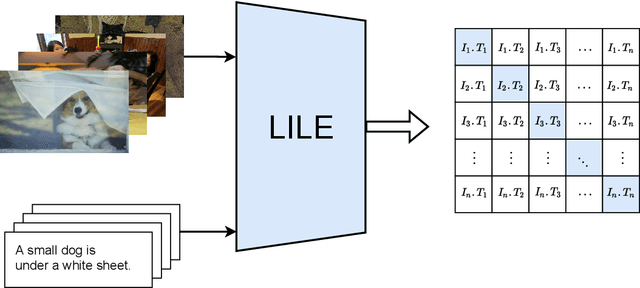
The volume of available data has grown dramatically in recent years in many applications. Furthermore, the age of networks that used multiple modalities separately has practically ended. Therefore, enabling bidirectional cross-modality data retrieval capable of processing has become a requirement for many domains and disciplines of research. This is especially true in the medical field, as data comes in a multitude of types, including various types of images and reports as well as molecular data. Most contemporary works apply cross attention to highlight the essential elements of an image or text in relation to the other modalities and try to match them together. However, regardless of their importance in their own modality, these approaches usually consider features of each modality equally. In this study, self-attention as an additional loss term will be proposed to enrich the internal representation provided into the cross attention module. This work suggests a novel architecture with a new loss term to help represent images and texts in the joint latent space. Experiment results on two benchmark datasets, i.e. MS-COCO and ARCH, show the effectiveness of the proposed method.