 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression of Recurrent Neural Networks using Matrix Factorization
Oct 19, 2023Compressing neural networks is a key step when deploying models for real-time or embedded applications. Factorizing the model's matrices using low-rank approximations is a promising method for achieving compression. While it is possible to set the rank before training, this approach is neither flexible nor optimal. In this work, we propose a post-training rank-selection method called Rank-Tuning that selects a different rank for each matrix. Used in combination with training adaptations, our method achieves high compression rates with no or little performance degradation. Our numerical experiments on signal processing tasks show that we can compress recurrent neural networks up to 14x with at most 1.4% relative performance reduction.
TrustGAN: Training safe and trustworthy deep learning models through generative adversarial networks
Nov 25, 2022Deep learning models have been developed for a variety of tasks and are deployed every day to work in real conditions. Some of these tasks are critical and models need to be trusted and safe, e.g. military communications or cancer diagnosis. These models are given real data, simulated data or combination of both and are trained to be highly predictive on them. However, gathering enough real data or simulating them to be representative of all the real conditions is: costly, sometimes impossible due to confidentiality and most of the time impossible. Indeed, real conditions are constantly changing and sometimes are intractable. A solution is to deploy machine learning models that are able to give predictions when they are confident enough otherwise raise a flag or abstain. One issue is that standard models easily fail at detecting out-of-distribution samples where their predictions are unreliable. We present here TrustGAN, a generative adversarial network pipeline targeting trustness. It is a deep learning pipeline which improves a target model estimation of the confidence without impacting its predictive power. The pipeline can accept any given deep learning model which outputs a prediction and a confidence on this prediction. Moreover, the pipeline does not need to modify this target model. It can thus be easily deployed in a MLOps (Machine Learning Operations) setting. The pipeline is applied here to a target classification model trained on MNIST data to recognise numbers based on images. We compare such a model when trained in the standard way and with TrustGAN. We show that on out-of-distribution samples, here FashionMNIST and CIFAR10, the estimated confidence is largely reduced. We observe similar conclusions for a classification model trained on 1D radio signals from AugMod, tested on RML2016.04C. We also publicly release the code.
A light neural network for modulation detection under impairments
Mar 27, 2020
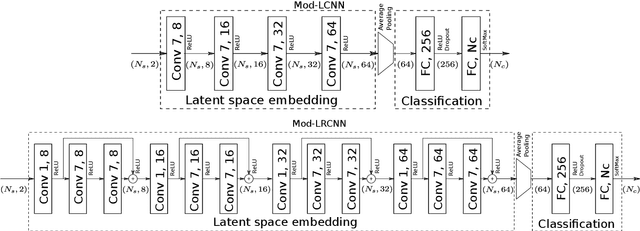

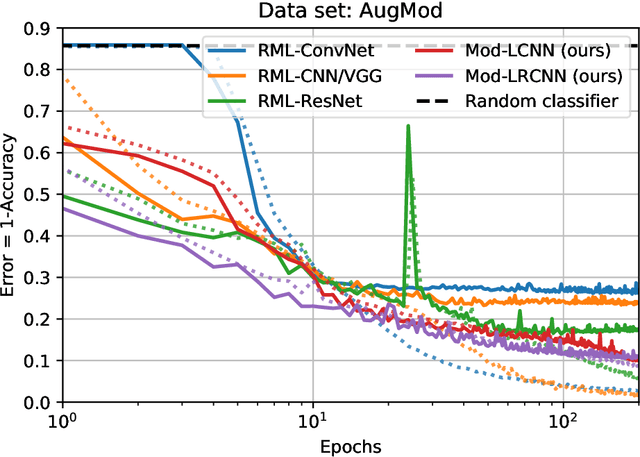
We present a neural network architecture able to efficiently detect modulation techniques in a portion of I/Q signals. This network is lighter by up to two orders of magnitude than other architectures working on the same or similar tasks. Moreover, the number of parameters does not depend on the signal duration, which allows processing stream of data, and results in a signal-length invariant network. In addition, we develop a custom simulator able to model the different impairments the propagation channel and the demodulator can bring to the recorded I/Q signal: random phase shifts, delays, roll-off, sampling rates, and frequency offsets. We benefit from this data set to train our neural network to be invariant to impairments and quantify its accuracy at disentangling between modulations under realistic real-life conditions.