 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN-HMM based Speaker Adaptive Emotion Recognition using Proposed Epoch and MFCC Features
Jun 04, 2018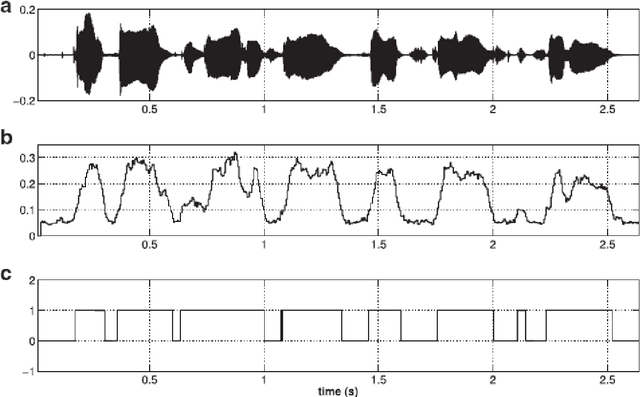

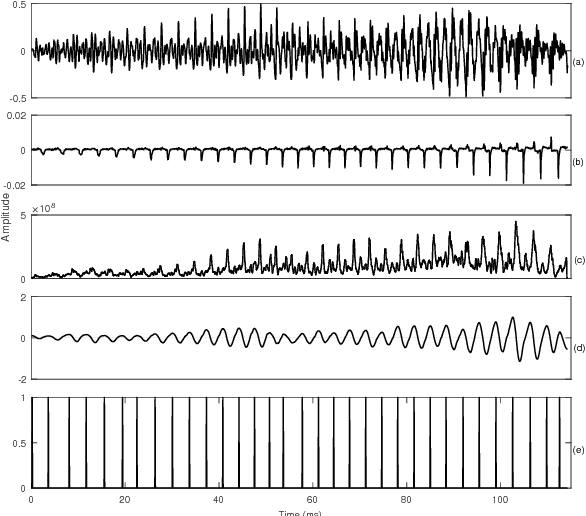
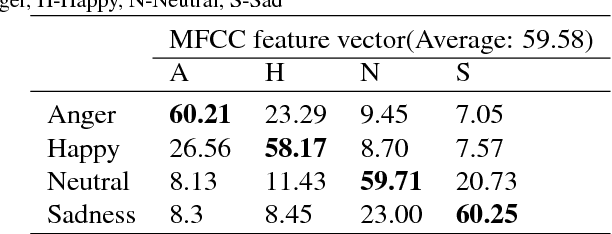
Speech is produced when time varying vocal tract system is excited with time varying excitation source. Therefore, the information present in a speech such as message, emotion, language, speaker is due to the combined effect of both excitation source and vocal tract system. However, there is very less utilization of excitation source features to recognize emotion. In our earlier work, we have proposed a novel method to extract glottal closure instants (GCIs) known as epochs. In this paper, we have explored epoch features namely instantaneous pitch, phase and strength of epochs for discriminating emotions. We have combined the excitation source features and the well known Male-frequency cepstral coefficient (MFCC) features to develop an emotion recognition system with improved performance. DNN-HMM speaker adaptive models have been developed using MFCC, epoch and combined features. IEMOCAP emotional database has been used to evaluate the models. The average accuracy for emotion recognition system when using MFCC and epoch features separately is 59.25% and 54.52% respectively. The recognition performance improves to 64.2% when MFCC and epoch features are combined.