 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeducing Kurdyka-Łojasiewicz exponent via inf-projection
Feb 10, 2019Kurdyka-{\L}ojasiewicz (KL) exponent plays an important role in estimating the convergence rate of many contemporary first-order methods. In particular, a KL exponent of $\frac12$ is related to local linear convergence. Nevertheless, KL exponent is in general extremely hard to estimate. In this paper, we show under mild assumptions that KL exponent is preserved via inf-projection. Inf-projection is a fundamental operation that is ubiquitous when reformulating optimization problems via the lift-and-project approach. By studying its operation on KL exponent, we show that the KL exponent is $\frac12$ for several important convex optimization models, including some semidefinite-programming-representable functions and functions that involve $C^2$-cone reducible structures, under conditions such as strict complementarity. Our results are applicable to concrete optimization models such as group fused Lasso and overlapping group Lasso. In addition, for nonconvex models, we show that the KL exponent of many difference-of-convex functions can be derived from that of their natural majorant functions, and the KL exponent of the Bregman envelope of a function is the same as that of the function itself. Finally, we estimate the KL exponent of the sum of the least squares function and the indicator function of the set of matrices of rank at most $k$.
Calculus of the exponent of Kurdyka-Łojasiewicz inequality and its applications to linear convergence of first-order methods
Jan 19, 2018In this paper, we study the Kurdyka-{\L}ojasiewicz (KL) exponent, an important quantity for analyzing the convergence rate of first-order methods. Specifically, we develop various calculus rules to deduce the KL exponent of new (possibly nonconvex and nonsmooth) functions formed from functions with known KL exponents. In addition, we show that the well-studied Luo-Tseng error bound together with a mild assumption on the separation of stationary values implies that the KL exponent is $\frac12$. The Luo-Tseng error bound is known to hold for a large class of concrete structured optimization problems, and thus we deduce the KL exponent of a large class of functions whose exponents were previously unknown. Building upon this and the calculus rules, we are then able to show that for many convex or nonconvex optimization models for applications such as sparse recovery, their objective function's KL exponent is $\frac12$. This includes the least squares problem with smoothly clipped absolute deviation (SCAD) regularization or minimax concave penalty (MCP) regularization and the logistic regression problem with $\ell_1$ regularization. Since many existing local convergence rate analysis for first-order methods in the nonconvex scenario relies on the KL exponent, our results enable us to obtain explicit convergence rate for various first-order methods when they are applied to a large variety of practical optimization models. Finally, we further illustrate how our results can be applied to establishing local linear convergence of the proximal gradient algorithm and the inertial proximal algorithm with constant step-sizes for some specific models that arise in sparse recovery.
Douglas-Rachford splitting for nonconvex optimization with application to nonconvex feasibility problems
Nov 05, 2015
We adapt the Douglas-Rachford (DR) splitting method to solve nonconvex feasibility problems by studying this method for a class of nonconvex optimization problem. While the convergence properties of the method for convex problems have been well studied, far less is known in the nonconvex setting. In this paper, for the direct adaptation of the method to minimize the sum of a proper closed function $g$ and a smooth function $f$ with a Lipschitz continuous gradient, we show that if the step-size parameter is smaller than a computable threshold and the sequence generated has a cluster point, then it gives a stationary point of the optimization problem. Convergence of the whole sequence and a local convergence rate are also established under the additional assumption that $f$ and $g$ are semi-algebraic. We also give simple sufficient conditions guaranteeing the boundedness of the sequence generated. We then apply our nonconvex DR splitting method to finding a point in the intersection of a closed convex set $C$ and a general closed set $D$ by minimizing the squared distance to $C$ subject to $D$. We show that if either set is bounded and the step-size parameter is smaller than a computable threshold, then the sequence generated from the DR splitting method is actually bounded. Consequently, the sequence generated will have cluster points that are stationary for an optimization problem, and the whole sequence is convergent under an additional assumption that $C$ and $D$ are semi-algebraic. We achieve these results based on a new merit function constructed particularly for the DR splitting method. Our preliminary numerical results indicate that our DR splitting method usually outperforms the alternating projection method in finding a sparse solution of a linear system, in terms of both the solution quality and the number of iterations taken.
Global convergence of splitting methods for nonconvex composite optimization
Nov 04, 2015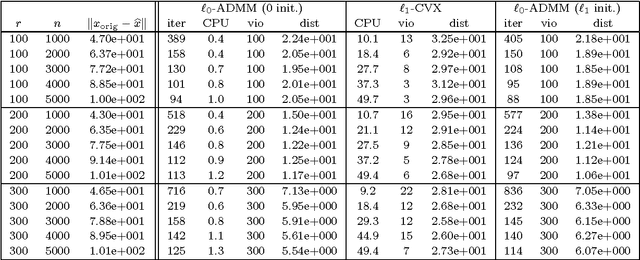

We consider the problem of minimizing the sum of a smooth function $h$ with a bounded Hessian, and a nonsmooth function. We assume that the latter function is a composition of a proper closed function $P$ and a surjective linear map $\cal M$, with the proximal mappings of $\tau P$, $\tau > 0$, simple to compute. This problem is nonconvex in general and encompasses many important applications in engineering and machine learning. In this paper, we examined two types of splitting methods for solving this nonconvex optimization problem: alternating direction method of multipliers and proximal gradient algorithm. For the direct adaptation of the alternating direction method of multipliers, we show that, if the penalty parameter is chosen sufficiently large and the sequence generated has a cluster point, then it gives a stationary point of the nonconvex problem. We also establish convergence of the whole sequence under an additional assumption that the functions $h$ and $P$ are semi-algebraic. Furthermore, we give simple sufficient conditions to guarantee boundedness of the sequence generated. These conditions can be satisfied for a wide range of applications including the least squares problem with the $\ell_{1/2}$ regularization. Finally, when $\cal M$ is the identity so that the proximal gradient algorithm can be efficiently applied, we show that any cluster point is stationary under a slightly more flexible constant step-size rule than what is known in the literature for a nonconvex $h$.