 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Mental Health Classification on Social Media
Dec 19, 2021

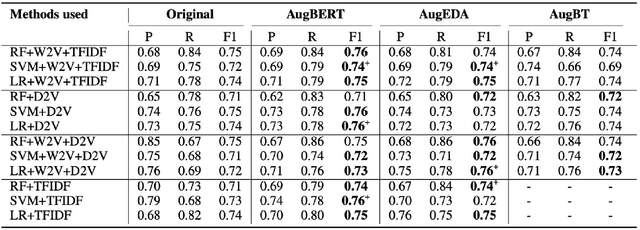
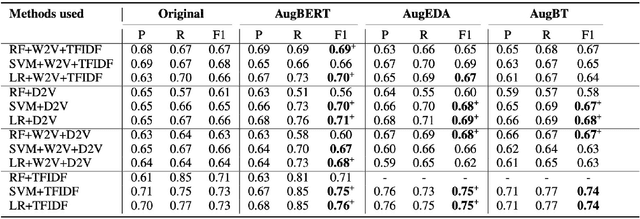
The mental disorder of online users is determined using social media posts. The major challenge in this domain is to avail the ethical clearance for using the user generated text on social media platforms. Academic re searchers identified the problem of insufficient and unlabeled data for mental health classification. To handle this issue, we have studied the effect of data augmentation techniques on domain specific user generated text for mental health classification. Among the existing well established data augmentation techniques, we have identified Easy Data Augmentation (EDA), conditional BERT, and Back Translation (BT) as the potential techniques for generating additional text to improve the performance of classifiers. Further, three different classifiers Random Forest (RF), Support Vector Machine (SVM) and Logistic Regression (LR) are employed for analyzing the impact of data augmentation on two publicly available social media datasets. The experiments mental results show significant improvements in classifiers performance when trained on the augmented data.
Aspect Term Extraction using Graph-based Semi-Supervised Learning
Feb 20, 2020



Aspect based Sentiment Analysis is a major subarea of sentiment analysis. Many supervised and unsupervised approaches have been proposed in the past for detecting and analyzing the sentiment of aspect terms. In this paper, a graph-based semi-supervised learning approach for aspect term extraction is proposed. In this approach, every identified token in the review document is classified as aspect or non-aspect term from a small set of labeled tokens using label spreading algorithm. The k-Nearest Neighbor (kNN) for graph sparsification is employed in the proposed approach to make it more time and memory efficient. The proposed work is further extended to determine the polarity of the opinion words associated with the identified aspect terms in review sentence to generate visual aspect-based summary of review documents. The experimental study is conducted on benchmark and crawled datasets of restaurant and laptop domains with varying value of labeled instances. The results depict that the proposed approach could achieve good result in terms of Precision, Recall and Accuracy with limited availability of labeled data.