 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new algorithm for Subgroup Set Discovery based on Information Gain
Jul 31, 2023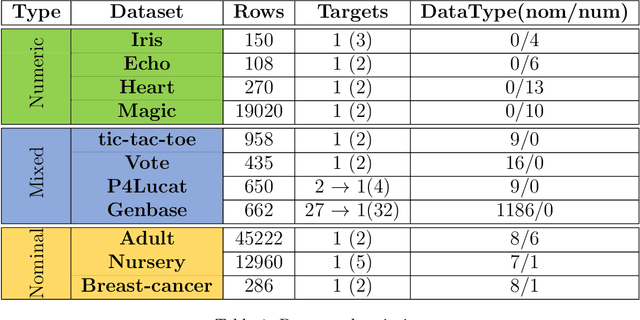

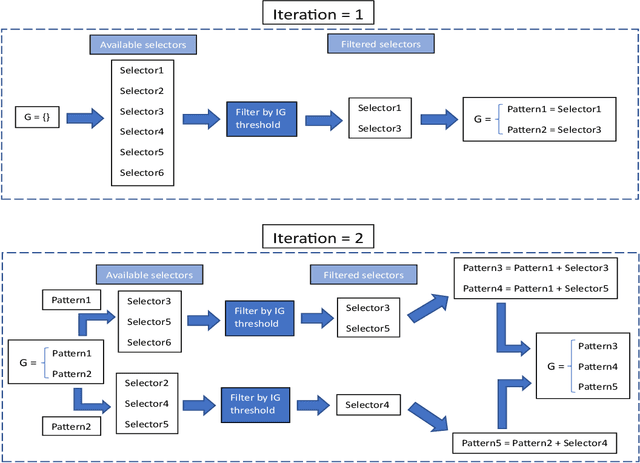
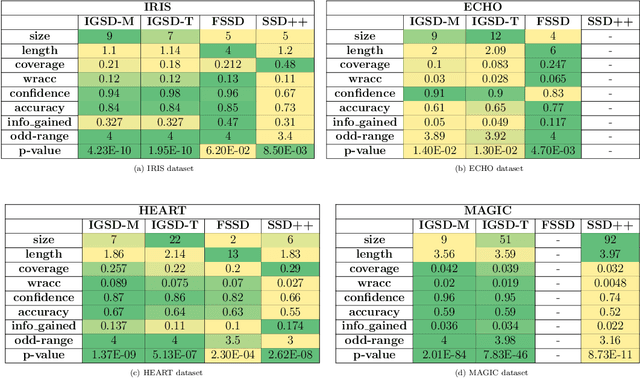
Pattern discovery is a machine learning technique that aims to find sets of items, subsequences, or substructures that are present in a dataset with a higher frequency value than a manually set threshold. This process helps to identify recurring patterns or relationships within the data, allowing for valuable insights and knowledge extraction. In this work, we propose Information Gained Subgroup Discovery (IGSD), a new SD algorithm for pattern discovery that combines Information Gain (IG) and Odds Ratio (OR) as a multi-criteria for pattern selection. The algorithm tries to tackle some limitations of state-of-the-art SD algorithms like the need for fine-tuning of key parameters for each dataset, usage of a single pattern search criteria set by hand, usage of non-overlapping data structures for subgroup space exploration, and the impossibility to search for patterns by fixing some relevant dataset variables. Thus, we compare the performance of IGSD with two state-of-the-art SD algorithms: FSSD and SSD++. Eleven datasets are assessed using these algorithms. For the performance evaluation, we also propose to complement standard SD measures with IG, OR, and p-value. Obtained results show that FSSD and SSD++ algorithms provide less reliable patterns and reduced sets of patterns than IGSD algorithm for all datasets considered. Additionally, IGSD provides better OR values than FSSD and SSD++, stating a higher dependence between patterns and targets. Moreover, patterns obtained for one of the datasets used, have been validated by a group of domain experts. Thus, patterns provided by IGSD show better agreement with experts than patterns obtained by FSSD and SSD++ algorithms. These results demonstrate the suitability of the IGSD as a method for pattern discovery and suggest that the inclusion of non-standard SD metrics allows to better evaluate discovered patterns.
Towards Automatic Learning of Heuristics for Mechanical Transformations of Procedural Code
Jan 25, 2017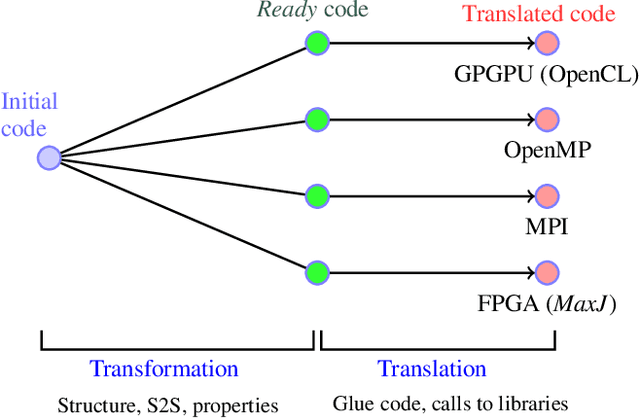
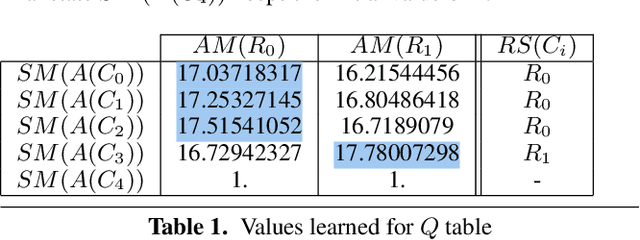
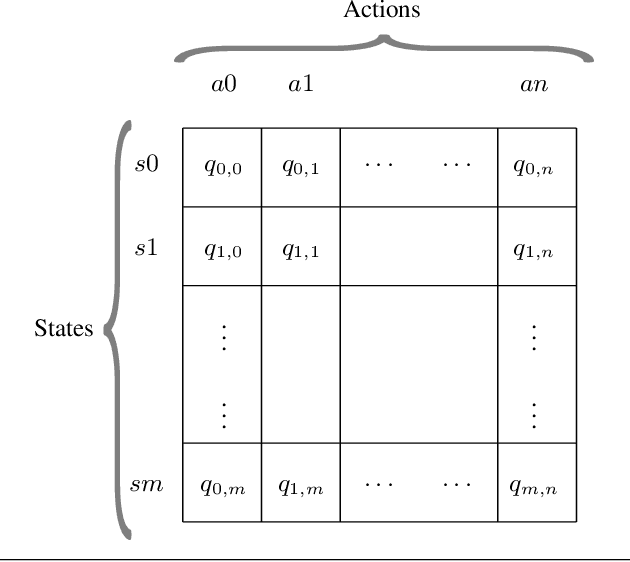
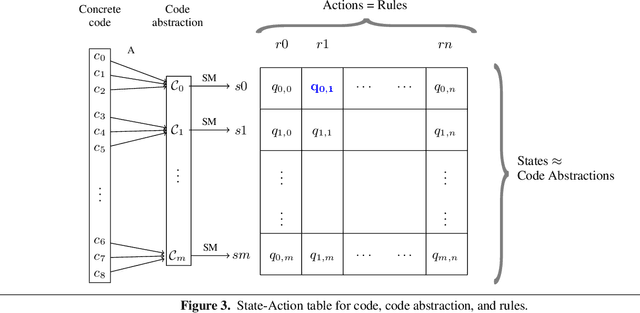
The current trends in next-generation exascale systems go towards integrating a wide range of specialized (co-)processors into traditional supercomputers. Due to the efficiency of heterogeneous systems in terms of Watts and FLOPS per surface unit, opening the access of heterogeneous platforms to a wider range of users is an important problem to be tackled. However, heterogeneous platforms limit the portability of the applications and increase development complexity due to the programming skills required. Program transformation can help make programming heterogeneous systems easier by defining a step-wise transformation process that translates a given initial code into a semantically equivalent final code, but adapted to a specific platform. Program transformation systems require the definition of efficient transformation strategies to tackle the combinatorial problem that emerges due to the large set of transformations applicable at each step of the process. In this paper we propose a machine learning-based approach to learn heuristics to define program transformation strategies. Our approach proposes a novel combination of reinforcement learning and classification methods to efficiently tackle the problems inherent to this type of systems. Preliminary results demonstrate the suitability of this approach.
* In Proceedings PROLE 2016, arXiv:1701.03069. This paper is based on arXiv:1603.03022, and has a thorough description of the proposed approach